
-
18 Einführung
-
18.1 Sampler
- FTP-Anfrage
- HTTP-Anfrage
- JDBC-Anfrage
- Java-Anfrage
- LDAP-Anfrage
- Erweiterte LDAP-Anfrage
- Greifen Sie auf den Log-Sampler zu
- BeanShell-Sampler
- JSR223-Sampler
- TCP-Sampler
- JMS-Verleger
- JMS-Abonnent
- JMS Punkt-zu-Punkt
- JUnit-Anfrage
- Mail-Reader-Beispiel
- Ablaufsteuerungsaktion (früher: Testaktion )
- SMTP-Sampler
- Betriebssystem-Prozess-Sampler
- MongoDB-Skript (VERALTET)
- Bolt-Anfrage
-
18.2 Logiksteuerungen
- Einfacher Controller
- Loop-Controller
- Einmaliger Controller
- Interleave-Controller
- Zufälliger Controller
- Controller für zufällige Reihenfolge
- Durchsatz-Controller
- Runtime-Controller
- Wenn Controller
- Während Controller
- Controller wechseln
- Für jeden Controller
- Modul-Controller
- Controller einbeziehen
- Transaktionscontroller
- Aufnahme-Controller
- Controller für kritische Abschnitte
-
18.3 Zuhörer
- Beispielergebnis Konfiguration speichern
- Diagrammergebnisse
- Assertionsergebnisse
- Ergebnisbaum anzeigen
- Aggregierter Bericht
- Ergebnisse in Tabelle anzeigen
- Einfacher Datenschreiber
- Aggregiertes Diagramm
- Reaktionszeitdiagramm
- Mailer-Visualizer
- BeanShell-Listener
- Kurzbericht
- Antworten in einer Datei speichern
- JSR223-Listener
- Zusammenfassende Ergebnisse generieren
- Vergleichsbehauptungs-Visualizer
- Backend-Listener
-
18.4 Konfigurationselemente
- CSV-Datensatzkonfig
- Standardeinstellungen für FTP-Anforderungen
- DNS-Cache-Manager
- HTTP-Autorisierungs-Manager
- HTTP-Cache-Manager
- HTTP-Cookie-Manager
- Standardeinstellungen für HTTP-Anforderungen
- HTTP-Header-Manager
- Standardeinstellungen für Java-Anforderungen
- JDBC-Verbindungskonfiguration
- Keystore-Konfiguration
- Login-Konfigurationselement
- Standardeinstellungen für LDAP-Anforderungen
- Standardwerte für erweiterte LDAP-Anforderungen
- TCP-Sampler-Konfiguration
- Benutzerdefinierte Variablen
- Zufällige Variable
- Zähler
- Einfaches Konfigurationselement
- MongoDB-Quellkonfiguration (VERALTET)
- Schraubenverbindungskonfiguration
- 18.5 Behauptungen
- 18.6 Timer
- 18.7 Vorprozessoren
- 18.8 Postprozessoren
- 18.9 Verschiedene Funktionen
18 Einführung ¶
18.1 Sampler ¶
Sampler führen die eigentliche Arbeit von JMeter aus. Jeder Sampler (außer Flow Control Action ) generiert ein oder mehrere Sample-Ergebnisse. Die Beispielergebnisse haben verschiedene Attribute (Erfolg/Fehler, verstrichene Zeit, Datengröße usw.) und können in den verschiedenen Listenern angezeigt werden.
FTP-Anfrage ¶
Die Latenz wird auf die Zeit eingestellt, die für die Anmeldung benötigt wird.

Parameter ¶
HTTP-Anfrage ¶
Mit diesem Sampler können Sie eine HTTP/HTTPS-Anfrage an einen Webserver senden. Außerdem können Sie steuern, ob JMeter HTML-Dateien nach Bildern und anderen eingebetteten Ressourcen parst und HTTP-Anforderungen sendet, um sie abzurufen. Die folgenden Arten von eingebetteten Ressourcen werden abgerufen:
- Bilder
- Applets
- Stylesheets (CSS) und Ressourcen, auf die von diesen Dateien verwiesen wird
- externe Skripte
- Frames, IFrames
- Hintergrundbilder (Körper, Tabelle, TD, TR)
- Hintergrundgeräusch
Der Standardparser ist org.apache.jmeter.protocol.http.parser.LagartoBasedHtmlParser . Dies kann mit der Eigenschaft " htmlparser.className " geändert werden - siehe jmeter.properties für Details.
Wenn Sie mehrere Anfragen an denselben Webserver senden, sollten Sie die Verwendung eines HTTP-Anforderungsstandard - Konfigurationselements in Betracht ziehen, damit Sie nicht für jede HTTP-Anforderung dieselben Informationen eingeben müssen.
Anstatt HTTP-Anforderungen manuell hinzuzufügen, können Sie sie auch mit dem HTTP(S) Test Script Recorder von JMeter erstellen. Dies kann Ihnen Zeit sparen, wenn Sie viele HTTP-Anforderungen oder Anforderungen mit vielen Parametern haben.
Zur Definition der Probenehmer werden drei verschiedene Testelemente verwendet:
- AJP/1.3-Sampler
- verwendet das Tomcat-mod_jk-Protokoll (ermöglicht das Testen von Tomcat im AJP-Modus, ohne Apache httpd zu benötigen) Der AJP-Sampler unterstützt das Hochladen mehrerer Dateien nicht; nur die erste Datei wird verwendet.
- HTTP-Anfrage
- Dies hat ein Implementierungs-Dropdown-Feld, das die zu verwendende HTTP-Protokollimplementierung auswählt:
- Java
- verwendet die von der JVM bereitgestellte HTTP-Implementierung. Dies hat einige Einschränkungen im Vergleich zu den HttpClient-Implementierungen - siehe unten.
- HTTPClient4
- verwendet Apache HttpComponents HttpClient 4.x.
- Leerer Wert
- legt die Implementierung nicht auf HTTP-Samplern fest, verlässt sich also auf HTTP-Anforderungsstandards, falls vorhanden, oder auf die jmeter.httpsampler- Eigenschaft, die in jmeter.properties definiert ist
- GraphQL-HTTP-Anfrage
- Dies ist eine GUI-Variante der HTTP-Anforderung , um bequemere UI-Elemente zum Anzeigen oder Bearbeiten von GraphQL-Abfragen , Variablen und Vorgangsnamen bereitzustellen , während sie automatisch unter der Haube mit demselben Sampler in HTTP-Argumente konvertiert werden. Dadurch werden die folgenden UI-Elemente ausgeblendet oder angepasst, da sie für GraphQL-über-HTTP/HTTPS-Anforderungen weniger bequem oder irrelevant sind:
- Methode : Es sind nur POST- und GET-Methoden verfügbar, die der GraphQL-over-HTTP-Spezifikation entsprechen. Die POST-Methode ist standardmäßig ausgewählt.
- Registerkarten „ Parameter “ und „ Post Body “: Sie können den Parameterinhalt stattdessen über die UI-Elemente „Query“, „Variables“ und „Operation Name“ anzeigen oder bearbeiten.
- Registerkarte Datei-Upload : irrelevant für GraphQL-Abfragen.
- Abschnitt „Eingebettete Ressourcen aus HTML-Dateien “ auf der Registerkarte „Erweitert“: irrelevant in GraphQL-JSON-Antworten.
Die Java-HTTP-Implementierung weist einige Einschränkungen auf:
- Es gibt keine Kontrolle darüber, wie Verbindungen wiederverwendet werden. Wenn eine Verbindung von JMeter freigegeben wird, kann sie von demselben Thread wiederverwendet werden oder nicht.
- Die API eignet sich am besten für die Single-Thread-Nutzung – verschiedene Einstellungen werden über Systemeigenschaften definiert und gelten daher für alle Verbindungen.
- Keine Unterstützung der Kerberos-Authentifizierung
- Clientbasierte Zertifikatstests mit Keystore Config werden nicht unterstützt.
- Bessere Kontrolle des Wiederholungsmechanismus
- Es unterstützt keine virtuellen Hosts.
- Es unterstützt nur die folgenden Methoden: GET , POST , HEAD , OPTIONS , PUT , DELETE und TRACE
- Bessere Kontrolle über das DNS-Caching mit dem DNS-Cache-Manager
Wenn die Anforderung eine Server- oder Proxy-Anmeldeautorisierung erfordert (dh wenn ein Browser ein Popup-Dialogfeld erstellen würde), müssen Sie auch ein HTTP-Autorisierungs-Manager - Konfigurationselement hinzufügen. Für normale Anmeldungen (dh wenn der Benutzer Anmeldeinformationen in ein Formular eingibt) müssen Sie herausfinden, was die Schaltfläche zum Absenden des Formulars bewirkt, und eine HTTP-Anfrage mit der entsprechenden Methode (normalerweise POST ) und den entsprechenden Parametern aus der Formulardefinition erstellen . Wenn die Seite HTTP verwendet, können Sie den JMeter-Proxy verwenden, um die Anmeldesequenz zu erfassen.
Für jeden Thread wird ein separater SSL-Kontext verwendet. Wenn Sie einen einzelnen SSL-Kontext verwenden möchten (nicht das Standardverhalten von Browsern), legen Sie die JMeter-Eigenschaft fest:
https.sessioncontext.shared=trueSeit Version 5.0 wird der SSL-Kontext standardmäßig während einer Thread-Gruppen-Iteration beibehalten und für jede Test-Iteration zurückgesetzt. Wenn in Ihrem Testplan derselbe Benutzer mehrmals iteriert, sollten Sie dies auf „false“ setzen.
httpclient.reset_state_on_thread_group_iteration=true
https.default.protocol=SSLv3
JMeter ermöglicht es auch, zusätzliche Protokolle zu aktivieren, indem die Eigenschaft https.socket.protocols geändert wird .
Wenn die Anfrage Cookies verwendet, benötigen Sie auch einen HTTP-Cookie-Manager . Sie können eines dieser Elemente der Thread-Gruppe oder der HTTP-Anforderung hinzufügen. Wenn Sie mehr als eine HTTP-Anforderung haben, die Autorisierungen oder Cookies benötigt, fügen Sie die Elemente der Thread-Gruppe hinzu. Auf diese Weise nutzen alle HTTP-Request-Controller die gleichen Authorization Manager- und Cookie Manager-Elemente.
Wenn die Anfrage eine Technik namens „URL-Umschreibung“ verwendet, um Sitzungen aufrechtzuerhalten, finden Sie weitere Konfigurationsschritte in Abschnitt 6.1 „Handhabung von Benutzersitzungen mit URL-Umschreibung “.




Parameter ¶
- es wird von HTTP Request Defaults bereitgestellt
- oder eine vollständige URL einschließlich Schema, Host und Port ( scheme://host:port ) wird im Pfadfeld festgelegt
Eine Daueraussage kann verwendet werden, um Antworten zu erkennen, deren Ausführung zu lange dauert.
Weitere Methoden können für den HttpClient4 vordefiniert werden, indem die JMeter-Eigenschaft httpsampler.user_defined_methods verwendet wird .
"Umleitung angefordert, aber followRedirects ist deaktiviert"Dies kann ignoriert werden.
JMeter reduziert Pfade der Form „ /../segment “ sowohl in absoluten als auch in relativen Umleitungs-URLs. Beispielsweise wird http://host/one/../two in http://host/two reduziert . Bei Bedarf kann dieses Verhalten durch Setzen der JMeter-Property httpsampler.redirect.removeslashdotdot=false unterdrückt werden
Außerdem können Sie angeben, ob jeder Parameter URL-codiert sein soll. Wenn Sie sich nicht sicher sind, was dies bedeutet, ist es wahrscheinlich am besten, es auszuwählen. Wenn Ihre Werte Zeichen wie die folgenden enthalten, ist normalerweise eine Codierung erforderlich.:
- ASCII-Steuerzeichen
- Nicht-ASCII-Zeichen
- Reservierte Zeichen: URLs verwenden einige Zeichen zur besonderen Verwendung bei der Definition ihrer Syntax. Wenn diese Zeichen nicht in ihrer besonderen Rolle innerhalb einer URL verwendet werden, müssen sie codiert werden, Beispiel: ' $ ', ' & ', ' + ', ' , ' , ' / ', ' : ', ' ; ', ' = ', ' ? ', ' @ '
- Unsichere Zeichen: Einige Zeichen können aus verschiedenen Gründen innerhalb von URLs missverstanden werden. Auch diese Zeichen sollten immer codiert werden, Beispiel: ' ', ' < ', ' > ', ' # ', ' % ', …
Wenn es sich um eine POST-, PUT- oder PATCH - Anforderung handelt und es eine einzelne Datei gibt, deren Attribut „Parametername“ (unten) weggelassen wird, wird die Datei als gesamter Anforderungstext gesendet, dh es werden keine Wrapper hinzugefügt. Damit können beliebige Bodys versendet werden. Diese Funktionalität ist für POST- Anforderungen und auch für PUT- Anforderungen vorhanden. Nachfolgend finden Sie einige weitere Informationen zur Parameterbehandlung.
Um den Wert der Quelladresse zu unterscheiden, wählen Sie den Typ davon aus:
- Wählen Sie IP/Hostname , um eine bestimmte IP-Adresse oder einen (lokalen) Hostnamen zu verwenden
- Wählen Sie Gerät aus, um die erste verfügbare Adresse für diese Schnittstelle auszuwählen, die entweder IPv4 oder IPv6 sein kann
- Wählen Sie Geräte-IPv4 aus, um die IPv4-Adresse des Gerätenamens auszuwählen ( z. B. eth0 , lo , em0 usw.)
- Wählen Sie Geräte-IPv6 aus, um die IPv6-Adresse des Gerätenamens auszuwählen (wie eth0 , lo , em0 usw.)
Diese Eigenschaft wird verwendet, um IP-Spoofing zu aktivieren. Sie überschreibt die standardmäßige lokale IP-Adresse für dieses Beispiel. Der JMeter-Host muss mehrere IP-Adressen haben (dh IP-Aliase, Netzwerkschnittstellen, Geräte). Der Wert kann ein Hostname, eine IP-Adresse oder ein Netzwerkschnittstellengerät wie „ eth0 “, „ lo “ oder „ wlan0 “ sein.
Wenn die Eigenschaft httpclient.localaddress definiert ist, wird diese für alle HttpClient-Anfragen verwendet.
Die folgenden Parameter sind nur für GraphQL-HTTP-Anfragen verfügbar :
Parameter ¶
Parameterbehandlung:
Wenn für die POST- und PUT -Methode keine zu sendende Datei vorhanden ist und die Namen der Parameter weggelassen werden, wird der Hauptteil durch Verketten aller Werte der Parameter erstellt. Beachten Sie, dass die Werte verkettet werden, ohne dass Zeilenendezeichen hinzugefügt werden. Diese können mit der Funktion __char() in den Wertfeldern hinzugefügt werden. Damit können beliebige Bodys versendet werden. Die Werte werden codiert, wenn das Codierungs-Flag gesetzt ist. Siehe auch MIME-Typ oben, wie Sie den gesendeten Anforderungsheader für
den Inhaltstyp steuern können.
Wenn bei anderen Methoden der Name des Parameters fehlt, wird der Parameter ignoriert. Dies ermöglicht die Verwendung von optionalen Parametern, die durch Variablen definiert werden.
Sie haben die Möglichkeit, zur Registerkarte Körperdaten zu wechseln, wenn eine Anfrage nur unbenannte Parameter (oder überhaupt keine Parameter) enthält. Diese Option ist (unter anderem) in folgenden Fällen nützlich:
- GWT-RPC-HTTP-Anforderung
- JSON-REST-HTTP-Anfrage
- XML-REST-HTTP-Anfrage
- SOAP-HTTP-Anfrage
Im Körperdatenmodus wird jede Zeile mit angehängtem CRLF gesendet , mit Ausnahme der letzten Zeile. Um ein CRLF nach der letzten Datenzeile zu senden , stellen Sie einfach sicher, dass darauf eine leere Zeile folgt. (Dies kann nicht gesehen werden, außer indem festgestellt wird, ob der Cursor auf die nachfolgende Zeile platziert werden kann.)



Methodenhandhabung:
Die Anforderungsmethoden GET , DELETE , POST , PUT und PATCH funktionieren ähnlich, außer dass ab 3.1 nur die POST -Methode mehrteilige Anforderungen oder das Hochladen von Dateien unterstützt. Der Hauptteil der PUT- und PATCH- Methode muss als einer der folgenden bereitgestellt werden:
- Definieren Sie den Körper als Datei mit leerem Feld für den Parameternamen. in diesem Fall wird der MIME-Typ als Inhaltstyp verwendet
- Definieren Sie den Körper als Parameterwert(e) ohne Namen
- Verwenden Sie die Registerkarte Körperdaten
Die Methoden GET , DELETE und POST haben eine zusätzliche Möglichkeit, Parameter über die Registerkarte Parameter zu übergeben. GET , DELETE , PUT und PATCH erfordern einen Content-Type. Wenn Sie keine Datei verwenden, hängen Sie einen Header-Manager an den Sampler an und definieren Sie dort den Content-Type.
JMeter-Scanantworten von eingebetteten Ressourcen. Es verwendet die Eigenschaft HTTPResponse.parsers , die eine Liste von Parser-IDs ist, zB htmlParser , cssParser und wmlParser . Für jede gefundene ID überprüft JMeter zwei weitere Eigenschaften:
- id.types – eine Liste von Inhaltstypen
- id.className – der Parser, der verwendet werden soll, um die eingebetteten Ressourcen zu extrahieren
Einzelheiten zu den Einstellungen finden Sie in der Datei jmeter.properties . Wenn die Eigenschaft HTTPResponse.parser nicht gesetzt ist, kehrt JMeter zum vorherigen Verhalten zurück, dh es werden nur Text-/HTML- Antworten gescannt
Langsame Verbindungen emulieren:HttpClient4 und Java Sampler unterstützen die Emulation langsamer Verbindungen; siehe die folgenden Einträge in jmeter.properties :
# Zeichen pro Sekunde > 0 definieren, um langsame Verbindungen zu emulieren #httpclient.socket.http.cps=0 #httpclient.socket.https.cps=0Der Java -Sampler unterstützt jedoch nur langsame HTTPS-Verbindungen.
Berechnung der Antwortgröße
Die HttpClient4- Implementierung enthält den Overhead in der Größe des Antworttexts, sodass der Wert möglicherweise größer als die Anzahl der Bytes im Antwortinhalt ist.
Handhabung
von Wiederholungen Standardmäßig wurde die Wiederholung sowohl für HttpClient4- als auch für Java-Implementierungen auf 0 gesetzt, was bedeutet, dass keine Wiederholung versucht wird.
Für HttpClient4 kann die Anzahl der Wiederholungen überschrieben werden, indem die relevante JMeter-Eigenschaft festgelegt wird, zum Beispiel:
httpclient4.retrycount=3
httpclient4.request_sent_retry_enabled=true
http.java.sampler.retries=3
Hinweis: Zertifikate entsprechen nicht den Algorithmuseinschränkungen
. Möglicherweise tritt
der folgende Fehler auf: java.security.cert.CertificateException: Zertifikate entsprechen nicht den Algorithmuseinschränkungen,
wenn Sie eine HTTPS-Anforderung auf einer Website mit einem SSL-Zertifikat (selbst oder einem der SSL-Zertifikate in seiner Vertrauenskette) mit einem Signaturalgorithmus, der MD2 verwendet (wie md2WithRSAEncryption ) oder mit einem SSL-Zertifikat mit einer Größe von weniger als 1024 Bit.
Dieser Fehler hängt mit der erhöhten Sicherheit in Java 8 zusammen.
Damit Sie Ihre HTTPS-Anforderung ausführen können, können Sie die Sicherheit Ihrer Java-Installation herabstufen, indem Sie die Java -Eigenschaft jdk.certpath.disabledAlgorithms bearbeiten . Entfernen Sie je nach Fall den MD2-Wert oder die Größenbeschränkung.
Diese Eigenschaft befindet sich in dieser Datei:
JAVA_HOME/jre/lib/security/java.security
Siehe Fehler 56357 für Details.
JDBC-Anfrage ¶
Mit diesem Sampler können Sie eine JDBC-Anforderung (eine SQL-Abfrage) an eine Datenbank senden.
Bevor Sie dies verwenden, müssen Sie ein Konfigurationselement für die JDBC-Verbindungskonfiguration einrichten
Wenn die Liste „Variablennamen“ bereitgestellt wird, werden die Variablen für jede von einer Select-Anweisung zurückgegebene Zeile mit dem Wert der entsprechenden Spalte eingerichtet (falls ein Variablenname bereitgestellt wird), und die Anzahl der Zeilen wird ebenfalls eingerichtet. Wenn die Select-Anweisung beispielsweise 2 Zeilen mit 3 Spalten zurückgibt und die Variablenliste A,,C ist, werden die folgenden Variablen eingerichtet:
A_#=2 (Anzahl Zeilen) A_1=Spalte 1, Zeile 1 A_2=Spalte 1, Zeile 2 C_#=2 (Anzahl Zeilen) C_1=Spalte 3, Zeile 1 C_2=Spalte 3, Zeile 2
Wenn die Select-Anweisung null Zeilen zurückgibt, werden die Variablen A_# und C_# auf 0 gesetzt , und es werden keine anderen Variablen gesetzt.
Alte Variablen werden bei Bedarf gelöscht. Wenn beispielsweise die erste Auswahl sechs Zeilen abruft und eine zweite Auswahl nur drei Zeilen zurückgibt, werden die zusätzlichen Variablen für die Zeilen vier, fünf und sechs entfernt.

Parameter ¶
- Aussage auswählen
- Update-Anweisung - verwenden Sie diese auch für Einfügungen und Löschungen
- Abrufbare Anweisung
- Vorbereitete Select-Anweisung
- Vorbereitete Aktualisierungsanweisung - verwenden Sie diese auch für Einfügungen und Löschungen
- Verpflichten
- Zurücksetzen
- Autocommit (falsch)
- Autocommit (wahr)
- Bearbeiten - Dies sollte eine Variablenreferenz sein, die eine der oben genannten Werte ergibt
- select * from t_customers where id=23
-
CALL SYSCS_UTIL.SYSCS_EXPORT_TABLE (null, ?, ?, null, null, null)
- Parameterwerte: Tabellenname , Dateiname
- Parametertypen: VARCHAR , VARCHAR
Die Liste muss in doppelte Anführungszeichen eingeschlossen werden, wenn einer der Werte ein Komma oder doppelte Anführungszeichen enthält, und alle eingebetteten doppelten Anführungszeichen müssen dies tun verdoppelt werden, zum Beispiel:
"Dbl-Zitat: "" und Komma: ,"
Diese sind als Felder in der Klasse java.sql.Types definiert , siehe zum Beispiel:
Javadoc für java.sql.Types .
Wenn nicht angegeben, wird " IN " angenommen, dh " DATE " ist dasselbe wie " IN DATE ".
Wenn der Typ nicht eines der Felder ist, die in java.sql.Types gefunden werden , akzeptiert JMeter auch die entsprechende Ganzzahl, z. B. da OracleTypes.CURSOR == -10 , können Sie " INOUT -10 " verwenden.
Es müssen so viele Typen vorhanden sein, wie es Platzhalter in der Anweisung gibt.
columnValue = vars.getObject("resultObject").get(0).get("Spaltenname");
- Als Zeichenfolge speichern (Standardeinstellung) – Alle Variablen in der Liste „Variablennamen“ werden als Zeichenfolgen gespeichert und durchlaufen keine Ergebnismenge , wenn sie in der Liste vorhanden ist. CLOB s werden in Strings umgewandelt. BLOB s werden in Strings konvertiert, als wären sie ein UTF-8-codiertes Byte-Array. Sowohl CLOB s als auch BLOB s werden nach jdbcsampler.max_retain_result_size Bytes abgeschnitten.
- Als Objekt speichern – Variablen vom Typ ResultSet in der Liste der Variablennamen werden als Objekt gespeichert und können in nachfolgenden Tests/Skripten aufgerufen und iteriert werden, iterieren nicht durch das ResultSet . CLOB s werden so behandelt, als ob Store As String ausgewählt wurde. BLOBs werden als Byte-Array gespeichert. Sowohl CLOB s als auch BLOB s werden nach jdbcsampler.max_retain_result_size Bytes abgeschnitten.
- Count Records - Variablen vom ResultSet- Typ werden iteriert, indem die Anzahl der Datensätze als Ergebnis angezeigt wird. Variablen werden als Strings gespeichert. Bei BLOBs wird die Größe des Objekts gespeichert.
Java-Anfrage ¶
Mit diesem Sampler können Sie eine Java-Klasse steuern, die die Schnittstelle org.apache.jmeter.protocol.java.sampler.JavaSamplerClient implementiert. Indem Sie Ihre eigene Implementierung dieser Schnittstelle schreiben, können Sie JMeter verwenden, um mehrere Threads, Eingabeparametersteuerung und Datenerfassung zu nutzen.
Das Pulldown-Menü enthält die Liste aller solcher Implementierungen, die JMeter in seinem Klassenpfad gefunden hat. Die Parameter können dann in der folgenden Tabelle angegeben werden - wie von Ihrer Implementierung definiert. Zwei einfache Beispiele ( JavaTest und SleepTest ) werden bereitgestellt.
Der Beispiel-Sampler JavaTest kann zum Überprüfen von Testplänen nützlich sein, da er es ermöglicht, Werte in fast allen Feldern festzulegen. Diese können dann von Assertions usw. verwendet werden. Die Felder ermöglichen die Verwendung von Variablen, sodass deren Werte leicht ersichtlich sind.

Parameter ¶
Die folgenden Parameter gelten für die SleepTest- und JavaTest- Implementierungen:
Parameter ¶
Die Schlafzeit wird wie folgt berechnet:
totalSleepTime = SleepTime + (System.currentTimeMillis() % SleepMask)
Für die JavaTest- Implementierung gelten zusätzlich folgende Parameter :
Parameter ¶
LDAP-Anfrage ¶
Wenn Sie mehrere Anfragen an denselben LDAP-Server senden, sollten Sie die Verwendung eines Standardkonfigurationselements für LDAP-Anfragen in Betracht ziehen, damit Sie nicht für jede LDAP-Anfrage dieselben Informationen eingeben müssen.
Auf die gleiche Weise wird das Login Config Element auch für Login und Passwort verwendet.
Es gibt zwei Möglichkeiten, Testfälle zum Testen eines LDAP-Servers zu erstellen.
- Eingebaute Testfälle.
- Benutzerdefinierte Testfälle.
Es gibt vier Testszenarien zum Testen von LDAP. Die Tests sind unten angegeben:
- Prüfung hinzufügen
- Eingebauter Test:
Dadurch wird ein vordefinierter Eintrag im LDAP-Server hinzugefügt und die Ausführungszeit berechnet. Nach Durchführung des Tests wird der erstellte Eintrag vom LDAP-Server gelöscht.
- Benutzerdefinierter Test:
Dadurch wird der Eintrag im LDAP-Server hinzugefügt. Der Benutzer muss alle Attribute in die Tabelle eingeben. Die Einträge werden aus der hinzuzufügenden Tabelle gesammelt. Die Ausführungszeit wird berechnet. Der erstellte Eintrag wird nach dem Test nicht gelöscht.
- Eingebauter Test:
- Test ändern
- Eingebauter Test:
Dadurch wird zuerst ein vordefinierter Eintrag erstellt, dann der erstellte Eintrag im LDAP-Server geändert und die Ausführungszeit berechnet. Nach Durchführung des Tests wird der erstellte Eintrag vom LDAP-Server gelöscht.
- Benutzerdefinierter Test:
Dadurch wird der Eintrag im LDAP-Server geändert. Der Benutzer muss alle Attribute in die Tabelle eingeben. Die Einträge werden aus der zu modifizierenden Tabelle gesammelt. Die Ausführungszeit wird berechnet. Der Eintrag wird nicht vom LDAP-Server gelöscht.
- Eingebauter Test:
- Suchtest
- Eingebauter Test:
Dadurch wird zuerst der Eintrag erstellt und dann gesucht, ob die Attribute verfügbar sind. Es berechnet die Ausführungszeit der Suchanfrage. Am Ende der Ausführung wird der erstellte Eintrag vom LDAP-Server gelöscht.
- Benutzerdefinierter Test:
Dadurch wird der benutzerdefinierte Eintrag (Suchfilter) in der Suchbasis (wieder vom Benutzer definiert) durchsucht. Die Einträge sollten im LDAP-Server verfügbar sein. Die Ausführungszeit wird berechnet.
- Eingebauter Test:
- Prüfung löschen
- Eingebauter Test:
Dadurch wird zunächst ein vordefinierter Eintrag erstellt, der dann vom LDAP-Server gelöscht wird. Die Ausführungszeit wird berechnet.
- Benutzerdefinierter Test:
Dadurch wird der benutzerdefinierte Eintrag im LDAP-Server gelöscht. Die Einträge sollten im LDAP-Server verfügbar sein. Die Ausführungszeit wird berechnet.
- Eingebauter Test:
Parameter ¶
Erweiterte LDAP-Anfrage ¶
Wenn Sie mehrere Anfragen an denselben LDAP-Server senden möchten, sollten Sie ein LDAP Extended Request Defaults Configuration Element verwenden, damit Sie nicht für jede LDAP-Anfrage dieselben Informationen eingeben müssen.

Es sind neun Testoperationen definiert. Diese Operationen sind unten angegeben:
- Fadenbindung
-
Jede LDAP-Anforderung ist Teil einer LDAP-Sitzung, daher sollte als Erstes eine Sitzung mit dem LDAP-Server gestartet werden. Zum Starten dieser Sitzung wird ein Thread-Bind verwendet, das der LDAP- Bind - Operation entspricht. Der Benutzer wird aufgefordert, einen Benutzernamen (Distinguished Name) und ein Passwort anzugeben , die zum Initiieren einer Sitzung verwendet werden. Wenn kein oder ein falsches Passwort angegeben wird, wird eine anonyme Sitzung gestartet. Seien Sie vorsichtig, das Weglassen des Passworts wird diesen Test nicht bestehen, ein falsches Passwort wird es tun. (Achtung: wird unverschlüsselt im Prüfplan gespeichert)
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinServernameDer Name (oder die IP-Adresse) des LDAP-Servers.JaHafenDie Portnummer, die der LDAP-Server überwacht. Wenn dies weggelassen wird, geht JMeter davon aus, dass der LDAP-Server auf dem Standardport (389) lauscht.NeinDNDer Distinguished Name des Basisobjekts, das für alle nachfolgenden Vorgänge verwendet wird. Es kann als Ausgangspunkt für alle Operationen verwendet werden. Sie können keine Operation auf einer höheren Ebene als diesem DN starten!NeinNutzernameVollständiger Distinguished Name des Benutzers, als den Sie eine Bindung herstellen möchten.NeinPasswortPasswort für den oben genannten Benutzer. Wenn es weggelassen wird, führt dies zu einer anonymen Bindung. Wenn es falsch ist, gibt der Sampler einen Fehler zurück und kehrt zu einer anonymen Bindung zurück. (Achtung: wird unverschlüsselt im Prüfplan gespeichert)NeinVerbindungstimeout (in Millisekunden)Timeout für Verbindung, bei Überschreitung wird die Verbindung abgebrochenNeinVerwenden Sie das sichere LDAP-ProtokollVerwenden Sie das Schema ldaps:// anstelle von ldap://NeinAllen Zertifikaten vertrauenAllen Zertifikaten vertrauen, wird nur verwendet, wenn Use Secure LDAP Protocol aktiviert istNein - Faden lösen
-
Dies ist einfach der Vorgang zum Beenden einer Sitzung. Dies ist gleich der LDAP-Operation „ unbind “.
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.Nein - Einzelne Bindung/Unbind
-
Dies ist eine Kombination der LDAP-Operationen „ Bind “ und „ Unbind “. Es kann für eine Authentifizierungsanfrage/Passwortprüfung für jeden Benutzer verwendet werden. Es öffnet eine neue Sitzung, nur um die Gültigkeit der Kombination aus Benutzer und Passwort zu überprüfen, und beendet die Sitzung erneut.
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinNutzernameVollständiger Distinguished Name des Benutzers, als den Sie eine Bindung herstellen möchten.JaPasswortPasswort für den oben genannten Benutzer. Wenn es weggelassen wird, führt dies zu einer anonymen Bindung. Wenn es falsch ist, gibt der Sampler einen Fehler zurück. (Achtung: wird unverschlüsselt im Prüfplan gespeichert)Nein - Eintrag umbenennen
-
Dies ist die LDAP-Operation „ moddn “. Es kann zum Umbenennen eines Eintrags verwendet werden, aber auch zum Verschieben eines Eintrags oder eines kompletten Teilbaums an eine andere Stelle im LDAP-Baum.
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinAlter EintragsnameDer aktuelle Distinguished Name des Objekts, das Sie umbenennen oder verschieben möchten, relativ zum angegebenen DN in der Thread-Bindeoperation.JaNeuer bekannter NameDer neue Distinguished Name des Objekts, das Sie umbenennen oder verschieben möchten, relativ zum angegebenen DN in der Thread-Bindeoperation.Ja - Prüfung hinzufügen
-
Dies ist die LDAP-Operation „ Hinzufügen “. Es kann verwendet werden, um beliebige Objekte zum LDAP-Server hinzuzufügen.
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinEintrags-DNDistinguished Name des Objekts, das Sie hinzufügen möchten, relativ zum angegebenen DN in der Thread-Bindeoperation.JaPrüfung hinzufügenEine Liste mit Attributen und ihren Werten, die Sie für das Objekt verwenden möchten. Wenn Sie ein Attribut mit mehreren Werten hinzufügen müssen, müssen Sie dasselbe Attribut mit den entsprechenden Werten mehrmals zur Liste hinzufügen.Ja - Prüfung löschen
-
Dies ist die LDAP - Löschoperation , sie kann verwendet werden, um ein Objekt aus dem LDAP-Baum zu löschen
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinLöschenDistinguished Name des Objekts, das Sie löschen möchten, relativ zum angegebenen DN in der Thread-Bindeoperation.Ja - Suchtest
-
Dies ist die LDAP -Suchoperation und wird zum Definieren von Suchen verwendet.
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinSuchbasisDistinguished Name der Unterstruktur, in der Sie suchen möchten, relativ zum angegebenen DN in der Thread-Bindeoperation.NeinSuchfiltersearchfilter, muss in LDAP-Syntax angegeben werden.JaZielfernrohrVerwenden Sie 0 für Basisobjekt-, 1 für eine Ebene- und 2 für eine Teilbaumsuche. (Standard = 0 )NeinGrößenbeschränkungGeben Sie die maximale Anzahl an Ergebnissen an, die Sie vom Server zurückgeben möchten. (Standard = 0 , was keine Begrenzung bedeutet.) Wenn der Sampler die maximale Anzahl von Ergebnissen erreicht, schlägt er mit Fehlercode 4 fehlNeinZeitlimitGeben Sie die maximale (CPU-)Zeit (in Millisekunden) an, die der Server für Ihre Suche aufwenden kann. Achtung, das sagt nichts über die Reaktionszeit aus. (Standard ist 0 , was keine Begrenzung bedeutet)NeinAttributeGeben Sie die Attribute an, die Sie zurückgegeben haben möchten, getrennt durch ein Semikolon. Ein leeres Feld gibt alle Attribute zurückNeinObjekt zurückgebenOb das Objekt zurückgegeben wird ( true ) oder nicht ( false ). Standard = falschNeinAliase dereferenzierenWenn true , werden Aliase dereferenziert, wenn false , werden sie ihnen nicht folgen (Standard = false )NeinDie Suchergebnisse parsen?Bei true werden die Suchergebnisse zu den Antwortdaten hinzugefügt. Bei false wird den Antwortdaten eine Markierung hinzugefügt, ob Ergebnisse gefunden wurden oder nicht.Nein - Modifikationstest
-
Dies ist die LDAP- Änderungsoperation . Es kann verwendet werden, um ein Objekt zu ändern. Es kann verwendet werden, um Werte eines Attributs hinzuzufügen, zu löschen oder zu ersetzen.
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinEintragsnameDistinguished Name des Objekts, das Sie ändern möchten, relativ zum angegebenen DN in der Thread-BindeoperationJaModifikationstestDer Attributwert-opCode verdreifacht.
Der opCode kann ein beliebiger gültiger LDAP-Operationscode sein ( add , delete , remove oder replace ). Wenn Sie bei einer Löschoperation
keinen Wert angeben , werden alle Werte des angegebenen Attributs gelöscht. Wenn Sie in einem Löschvorgang einen Wert angeben , wird nur der angegebene Wert gelöscht. Wenn dieser Wert nicht vorhanden ist, besteht der Probenehmer den Test nicht.Ja - Vergleichen
-
Dies ist die LDAP- Vergleichsoperation . Es kann verwendet werden, um den Wert eines bestimmten Attributs mit einem bereits bekannten Wert zu vergleichen. In Wirklichkeit wird dies hauptsächlich verwendet, um zu überprüfen, ob eine bestimmte Person Mitglied einer Gruppe ist. In einem solchen Fall können Sie den DN des Benutzers als vorgegebenen Wert mit den Werten im Attribut „ member “ eines Objekts vom Typ groupOfNames vergleichen . Wenn der Vergleichsvorgang fehlschlägt, schlägt dieser Test mit dem Fehlercode 49 fehl .
Parameter
AttributBeschreibungErforderlichNameBeschreibender Name für diesen Sampler, der in der Baumstruktur angezeigt wird.NeinEintrags-DNDer aktuelle Distinguished Name des Objekts, dessen Attribut Sie vergleichen möchten, relativ zum angegebenen DN in der Thread-Bindeoperation.JaFilter vergleichenIn der Form " Attribut=Wert "Ja
Zugriffsprotokoll-Sampler ¶
AccessLogSampler wurde entwickelt, um Zugriffsprotokolle zu lesen und HTTP-Anforderungen zu generieren. Für diejenigen, die mit dem Zugriffsprotokoll nicht vertraut sind, es ist das Protokoll, das der Webserver über jede akzeptierte Anfrage führt. Das heißt jedes Bild, CSS-Datei, JavaScript-Datei, HTML-Datei, …
Tomcat verwendet das gängige Format für Zugriffsprotokolle. Dies bedeutet, dass jeder Webserver, der das allgemeine Protokollformat verwendet, den AccessLogSampler verwenden kann. Zu den Servern, die ein gängiges Protokollformat verwenden, gehören: Tomcat, Resin, Weblogic und SunOne. Das übliche Protokollformat sieht folgendermaßen aus:
127.0.0.1 - - [21/Oct/2003:05:37:21 -0500] "GET /index.jsp?%2Findex.jsp= HTTP/1.1" 200 8343
Für die Zukunft könnte es sinnvoll sein, Einträge herauszufiltern, die keinen Antwortcode von 200 haben . Das Erweitern des Samplers sollte ziemlich einfach sein. Es gibt zwei Schnittstellen, die Sie implementieren müssen:
- org.apache.jmeter.protocol.http.util.accesslog.LogParser
- org.apache.jmeter.protocol.http.util.accesslog.Generator
Die aktuelle Implementierung von AccessLogSampler verwendet den Generator, um einen neuen HTTPSampler zu erstellen. Servername, Port und Get-Images werden von AccessLogSampler festgelegt. Als nächstes wird der Parser mit der Ganzzahl 1 aufgerufen und weist ihn an, einen Eintrag zu analysieren. Danach wird HTTPSampler.sample() aufgerufen, um die Anfrage zu stellen.
samp = (HTTPSampler) GENERATOR.generateRequest(); samp.setDomain(this.getDomain()); samp.setPort (this.getPort()); samp.setImageParser (this.isImageParser()); PARSER.parse(1); res = sample.sample(); res.setSampleLabel(samp.toString());Die erforderlichen Methoden in LogParser sind:
- setGenerator(Generator)
- analysieren (int)
Klassen, die die Generator -Schnittstelle implementieren, sollten eine konkrete Implementierung für alle Methoden bereitstellen. Ein Beispiel für die Implementierung einer der beiden Schnittstellen finden Sie unter StandardGenerator und TCLogParser .

(Beta-Code)
Parameter ¶
Der TCLogParser verarbeitet das Zugriffsprotokoll unabhängig für jeden Thread. SharedTCLogParser und OrderPreservingLogParser teilen sich den Zugriff auf die Datei, dh jeder Thread bekommt den nächsten Eintrag im Log.
Der SessionFilter soll Cookies über Threads hinweg handhaben. Es filtert keine Einträge heraus, sondern modifiziert den Cookie-Manager so, dass die Cookies für eine bestimmte IP jeweils von einem einzigen Thread verarbeitet werden. Wenn zwei Threads versuchen, Proben von derselben Client-IP-Adresse zu verarbeiten, muss einer warten, bis der andere fertig ist.
Der LogFilter soll das Filtern von Zugriffsprotokolleinträgen nach Dateinamen und Regex sowie das Ersetzen von Dateierweiterungen ermöglichen. Allerdings ist dies derzeit nicht über die GUI konfigurierbar, also nicht wirklich nutzbar.
BeanShell-Sampler ¶
Mit diesem Sampler können Sie einen Sampler mit der Skriptsprache BeanShell schreiben.
Ausführliche Informationen zur Verwendung von BeanShell finden Sie auf der BeanShell-Website.
Das Testelement unterstützt die Schnittstellenmethoden ThreadListener und TestListener . Diese müssen in der Initialisierungsdatei definiert werden. Beispieldefinitionen finden Sie in der Datei BeanShellListeners.bshrc .
Der BeanShell-Sampler unterstützt auch die Interruptible -Schnittstelle. Die Methode interrupt() kann im Skript oder in der Init-Datei definiert werden.

Parameter ¶
- Parameter
- Zeichenfolge, die die Parameter als einzelne Variable enthält
- bsh.args
- String-Array mit Parametern, aufgeteilt auf Leerzeichen
Wenn die Eigenschaft „ beanshell.sampler.init “ definiert ist, wird sie als Name einer Quelldatei an den Interpreter übergeben. Dies kann verwendet werden, um allgemeine Methoden und Variablen zu definieren. Im Verzeichnis bin befindet sich eine Beispiel-Init-Datei: BeanShellSampler.bshrc .
Wenn eine Skriptdatei bereitgestellt wird, wird diese verwendet, ansonsten wird das Skript verwendet.
BeanShell unterstützt derzeit keine Java 5-Syntax wie Generika und die erweiterte for-Schleife.
Vor dem Aufruf des Skripts werden einige Variablen im BeanShell-Interpreter eingerichtet:
Der Inhalt des Parameterfeldes wird in die Variable „ Parameters “ geschrieben. Die Zeichenfolge wird auch in separate Token aufgeteilt, wobei ein einzelnes Leerzeichen als Trennzeichen verwendet wird, und die resultierende Liste wird im Zeichenfolgen-Array bsh.args gespeichert .
Die vollständige Liste der eingerichteten BeanShell-Variablen lautet wie folgt:
- log - der Logger
- Label - das Sampler-Label
- FileName – der Dateiname, falls vorhanden
- Parameter - Text aus dem Feld Parameter
- bsh.args - die Parameter, aufgeteilt wie oben beschrieben
- SampleResult – Zeiger auf das aktuelle SampleResult
- ResponseCode ist standardmäßig 200
- ResponseMessage ist standardmäßig " OK "
- IsSuccess ist standardmäßig wahr
- ctx - JMeterContext
-
vars - JMeterVariables - zB
vars.get("VAR1"); vars.put("VAR2","Wert"); vars.remove("VAR3"); vars.putObject("OBJ1",neues Objekt()); -
Requisiten - JMeterProperties (Klasse java.util.Properties ) - zB
props.get("START.HMS"); props.put("PROP1","1234");
Wenn das Skript abgeschlossen ist, wird die Kontrolle an den Sampler zurückgegeben und kopiert den Inhalt der folgenden Skriptvariablen in die entsprechenden Variablen in SampleResult :
- ResponseCode - zum Beispiel 200
- Antwortnachricht – zum Beispiel „ OK “
- IsSuccess – wahr oder falsch
Das SampleResult ResponseData wird aus dem Rückgabewert des Skripts festgelegt. Wenn das Skript null zurückgibt, kann es die Antwort direkt festlegen, indem es die Methode SampleResult.setResponseData(data) verwendet , wobei data entweder ein String oder ein Byte-Array ist. Der Datentyp ist standardmäßig „ Text “, kann aber mithilfe der Methode SampleResult.setDataType(SampleResult.BINARY) auf Binär gesetzt werden .
Die Variable SampleResult gibt dem Skript vollen Zugriff auf alle Felder und Methoden in SampleResult . Das Skript hat beispielsweise Zugriff auf die Methoden setStopThread(boolean) und setStopTest(boolean) . Hier ist ein einfaches (nicht sehr nützliches!) Beispielskript:
if (bsh.args[0].equalsIgnoreCase("StopThread")) {
log.info("Stopp-Thread erkannt!");
SampleResult.setStopThread(true);
}
return "Daten aus Probe mit Label "+Label;
//oder
SampleResult.setResponseData("Meine Daten");
gib null zurück;
Ein weiteres Beispiel: Stellen Sie
sicher, dass die Eigenschaft beanshell.sampler.init=BeanShellSampler.bshrc in jmeter.properties definiert ist . Das folgende Skript zeigt die Werte aller Variablen im ResponseData -Feld:
getVariables zurückgeben ();
Einzelheiten zu den für die verschiedenen Klassen verfügbaren Methoden ( JMeterVariables , SampleResult usw.) finden Sie im Javadoc oder im Quellcode. Beachten Sie jedoch, dass der Missbrauch jeglicher Methoden subtile Fehler verursachen kann, die möglicherweise schwer zu finden sind.
JSR223-Sampler ¶
Der JSR223-Sampler ermöglicht die Verwendung von JSR223-Skriptcode zur Durchführung eines Beispiels oder einiger Berechnungen, die zum Erstellen/Aktualisieren von Variablen erforderlich sind.
SampleResult.setIgnore();Dieser Aufruf hat folgende Auswirkungen:
- SampleResult wird nicht an SampleListener wie View Results Tree, Summariser ... geliefert.
- SampleResult wird weder in Assertions noch in PostProcessors ausgewertet
- SampleResult wird ausgewertet, um den Status des letzten Samples (${JMeterThread.last_sample_ok}) und ThreadGroup „Action to be take after a Sampler error“ (seit JMeter 5.4) zu berechnen.
Die JSR223-Testelemente verfügen über ein Feature (Kompilierung), das die Leistung erheblich steigern kann. So profitieren Sie von dieser Funktion:
- Verwenden Sie Skriptdateien, anstatt sie einzubetten. Dadurch wird JMeter sie kompilieren, wenn diese Funktion in ScriptEngine verfügbar ist, und sie zwischenspeichern.
- Oder Verwenden Sie Skripttext und aktivieren Sie die Eigenschaft
Kompiliertes Skript zwischenspeichern, falls verfügbar .
Stellen Sie bei Verwendung dieser Funktion sicher, dass Ihr Skriptcode keine JMeter-Variablen oder JMeter-Funktionsaufrufe direkt im Skriptcode verwendet, da beim Caching nur die erste Ersetzung zwischengespeichert würde. Verwenden Sie stattdessen Skriptparameter.Um vom Caching und der Kompilierung zu profitieren, muss die für die Skripterstellung verwendete Sprach-Engine die JSR223 Compilable- Schnittstelle implementieren (Groovy ist eine davon, Java, Beanshell und Javascript sind es nicht).Wenn Sie Groovy als Skriptsprache verwenden und Compiliertes Skript zwischenspeichern, falls verfügbar , nicht aktivieren (obwohl Caching empfohlen wird), sollten Sie diese JVM-Eigenschaft -Dgroovy.use.classvalue=true aufgrund eines Groovy-Speicherlecks ab Version 2.4.6 setzen, siehe:
jsr223.compiled_scripts_cache_size=100

props.get("START.HMS");
props.put("PROP1","1234");
Parameter ¶
Beachten Sie, dass einige Sprachen wie Velocity möglicherweise eine andere Syntax für JSR223-Variablen verwenden, z
$log.debug("Hallo" + $vars.get("a"));für Geschwindigkeit.
Wenn eine Skriptdatei bereitgestellt wird, wird diese verwendet, ansonsten wird das Skript verwendet.
Vor dem Aufruf des Skripts werden einige Variablen eingerichtet. Beachten Sie, dass dies JSR223-Variablen sind - dh sie können direkt im Skript verwendet werden.
- log - der Logger
- Label - das Sampler-Label
- FileName – der Dateiname, falls vorhanden
- Parameter - Text aus dem Feld Parameter
- args - die Parameter, aufgeteilt wie oben beschrieben
- SampleResult – Zeiger auf das aktuelle SampleResult
- sampler - ( Sampler ) - Zeiger auf aktuellen Sampler
- ctx - JMeterContext
-
vars - JMeterVariables - zB
vars.get("VAR1"); vars.put("VAR2","Wert"); vars.remove("VAR3"); vars.putObject("OBJ1",neues Objekt()); -
Requisiten - JMeterProperties (Klasse java.util.Properties ) - zB
props.get("START.HMS"); props.put("PROP1","1234"); - OUT - System.out - zB OUT.println("Nachricht")
Das SampleResult ResponseData wird aus dem Rückgabewert des Skripts festgelegt. Wenn das Skript null zurückgibt , kann es die Antwort direkt festlegen, indem es die Methode SampleResult.setResponseData(data) verwendet , wobei data entweder ein String oder ein Byte-Array ist. Der Datentyp ist standardmäßig „ Text “, kann aber mithilfe der Methode SampleResult.setDataType(SampleResult.BINARY) auf Binär gesetzt werden .
Die SampleResult-Variable gibt dem Skript vollen Zugriff auf alle Felder und Methoden in SampleResult. Das Skript hat beispielsweise Zugriff auf die Methoden setStopThread(boolean) und setStopTest(boolean) .
Im Gegensatz zum BeanShell-Sampler setzt der JSR223-Sampler den ResponseCode , die ResponseMessage und den Sample-Status nicht über Skriptvariablen. Derzeit ist die einzige Möglichkeit, diese zu ändern, über die SampleResult- Methoden:
- SampleResult.setSuccessful(true/false)
- SampleResult.setResponseCode("Code")
- SampleResult.setResponseMessage("Nachricht")
TCP-Sampler ¶
Der TCP-Sampler öffnet eine TCP/IP-Verbindung zum angegebenen Server. Es sendet dann den Text und wartet auf eine Antwort.
Wenn „ Verbindung wiederverwenden“ ausgewählt ist, werden Verbindungen zwischen Samplern im selben Thread geteilt, vorausgesetzt, dass genau dieselbe Hostnamenzeichenfolge und derselbe Port verwendet werden. Unterschiedliche Hosts/Port-Kombinationen verwenden unterschiedliche Verbindungen, ebenso wie unterschiedliche Threads. Wenn sowohl „ Verbindung wiederverwenden “ als auch „ Verbindung schließen “ ausgewählt sind, wird der Socket nach dem Ausführen des Samplers geschlossen. Beim nächsten Sampler wird ein weiterer Socket erstellt. Möglicherweise möchten Sie am Ende jeder Fadenschleife einen Sockel schließen.
Wenn ein Fehler erkannt wird – oder „ Reuse Connection “ nicht ausgewählt ist – wird der Socket geschlossen. Beim nächsten Sample wird ein weiterer Socket wieder geöffnet.
Die folgenden Eigenschaften können verwendet werden, um seinen Betrieb zu steuern:
- tcp.status.präfix
- Text, der einer Statusnummer vorangestellt ist
- tcp.status.suffix
- Text, der einer Statusnummer folgt
- tcp.status.properties
- Name der Eigenschaftsdatei, um Statuscodes in Meldungen umzuwandeln
- tcp.handler
- Name der TCP-Handler-Klasse (Standard TCPClientImpl ) – wird nur verwendet, wenn nicht auf der GUI angegeben
Benutzer können ihre eigene Implementierung bereitstellen. Die Klasse muss org.apache.jmeter.protocol.tcp.sampler.TCPClient erweitern .
Die folgenden Implementierungen werden derzeit bereitgestellt.
- TCPClientImpl
- BinaryTCPClientImpl
- LengthPrefixedBinaryTCPClientImpl
- TCPClientImpl
- Diese Implementierung ist ziemlich einfach. Beim Lesen der Antwort wird bis zum Ende des Zeilenbytes gelesen, wenn dies durch Setzen der Eigenschaft tcp.eolByte definiert ist , ansonsten bis zum Ende des Eingabestroms. Sie können die Zeichensatzcodierung steuern, indem Sie tcp.charset festlegen , das standardmäßig die Standardcodierung der Plattform ist.
- BinaryTCPClientImpl
- Diese Implementierung wandelt die GUI-Eingabe, die eine Hex-codierte Zeichenfolge sein muss, in eine Binärdatei um und führt beim Lesen der Antwort das Gegenteil aus. Beim Lesen der Antwort wird bis zum Ende des Nachrichtenbytes gelesen, wenn dies durch Setzen der Eigenschaft tcp.BinaryTCPClient.eomByte definiert ist , ansonsten bis zum Ende des Eingabestroms.
- LengthPrefixedBinaryTCPClientImpl
- Diese Implementierung erweitert BinaryTCPClientImpl, indem den binären Nachrichtendaten ein Byte mit binärer Länge vorangestellt wird. Das Längenpräfix beträgt standardmäßig 2 Byte. Dies kann durch Setzen der Eigenschaft tcp.binarylength.prefix.length geändert werden .
- Behandlung von Zeitüberschreitungen
- Wenn das Timeout gesetzt ist, wird der Lesevorgang beendet, wenn dieses abgelaufen ist. Wenn Sie also ein eolByte / eomByte verwenden , achten Sie darauf, dass das Timeout ausreichend lang ist, da sonst der Lesevorgang vorzeitig abgebrochen wird.
- Antwortbehandlung
-
Wenn tcp.status.prefix definiert ist, wird die Antwortnachricht nach dem darauffolgenden Text bis zum Suffix durchsucht. Wenn ein solcher Text gefunden wird, wird er verwendet, um den Antwortcode festzulegen. Die Antwortnachricht wird dann aus der Eigenschaftsdatei (falls vorhanden) abgerufen.
Response Codes im Bereich „ 400 “ – „ 499 “ und „ 500 “ – „ 599 “ gelten derzeit als Fehler; alle anderen sind erfolgreich. [Dies muss konfigurierbar gemacht werden!]Verwendung von Prä- und Suffix ¶Wenn beispielsweise das Präfix = " [ " und das Suffix = " ] " ist, dann die folgende Antwort:
[J28] XI123,23,GBP,CR
hätte den Antwortcode J28 .
Steckdosen werden am Ende eines Testlaufs getrennt.

Parameter ¶
JMS-Publisher ¶
JMS Publisher veröffentlicht Nachrichten an einem bestimmten Ziel (Thema/Warteschlange). Für diejenigen, die mit JMS nicht vertraut sind: Es ist die J2EE-Spezifikation für Messaging. Es gibt zahlreiche JMS-Server auf dem Markt und mehrere Open-Source-Optionen.

Parameter ¶
- Aus Datei
- bedeutet, dass die referenzierte Datei von allen Beispielen gelesen und wiederverwendet wird. Wenn sich der Dateiname ändert, wird er seit JMeter 3.0 neu geladen
- Zufällige Datei aus dem unten angegebenen Ordner
- bedeutet, dass eine zufällige Datei aus dem unten angegebenen Ordner ausgewählt wird, dieser Ordner muss entweder Dateien mit der Erweiterung .dat für Bytes-Nachrichten oder Dateien mit der Erweiterung .txt oder .obj für Objekt- oder Textnachrichten enthalten
- Textbereich
- Die Nachricht, die entweder für Text- oder Objektnachrichten verwendet werden soll
- ROH :
- Keine Variablenunterstützung aus der Datei und Laden mit Standard-Systemzeichensatz.
- STANDARD :
- Datei mit Standard-Systemcodierung laden, mit Ausnahme von XML, das auf dem XML-Prolog basiert. Wenn die Datei Variablen enthält, werden diese verarbeitet.
- Standardzeichensätze :
- Die angegebene Codierung (gültig oder nicht) wird zum Lesen der Datei und zum Verarbeiten von Variablen verwendet
Für den MapMessage-Typ liest JMeter die Quelle als Textzeilen. Jede Zeile muss 3 Felder haben, die durch Kommas getrennt sind. Die Felder sind:
- Name des Eintrags
- Name der Objektklasse, z. B. „ String “ (setzt java.lang -Paket voraus, wenn nicht angegeben)
- Wert der Objektzeichenfolge
name,String,Beispiel Größe, Ganzzahl, 1234
- Legen Sie das JAR, das Ihr Objekt und seine Abhängigkeiten enthält, im Ordner jmeter_home/lib/ ab
- Serialisieren Sie Ihr Objekt als XML mit XStream
- Geben Sie das Ergebnis entweder in eine Datei mit der Endung .txt oder .obj ein oder legen Sie den XML-Inhalt direkt im Textbereich ab
Die folgende Tabelle zeigt einige Werte, die bei der Konfiguration von JMS hilfreich sein können:
| Apache ActiveMQ | Werte) | Kommentar |
|---|---|---|
| Kontextfabrik | org.apache.activemq.jndi.ActiveMQInitialContextFactory | . |
| Anbieter-URL | vm://localhost | |
| Anbieter-URL | vm:(broker:(vm://localhost)?persistent=false) | Persistenz deaktivieren |
| Warteschlangenreferenz | dynamicQueues/QUEUENAME | Definieren Sie den QUEUENAME dynamisch für JNDI |
| Themenreferenz | dynamische Themen/TOPICNAME | Definieren Sie TOPICNAME dynamisch für JNDI |
JMS-Abonnent ¶
Der JMS-Abonnent abonniert Nachrichten in einem bestimmten Ziel (Thema oder Warteschlange). Für diejenigen, die mit JMS nicht vertraut sind: Es ist die J2EE-Spezifikation für Messaging. Es gibt zahlreiche JMS-Server auf dem Markt und mehrere Open-Source-Optionen.

Parameter ¶
- MessageConsumer.receive()
- ruft Receive() für jede angeforderte Nachricht auf. Behält die Verbindung zwischen Samples bei, ruft aber keine Nachrichten ab, es sei denn, der Sampler ist aktiv. Dies ist am besten für Warteschlangenabonnements geeignet.
- MessageListener.onMessage()
- richtet einen Listener ein, der alle eingehenden Nachrichten in einer Warteschlange speichert. Der Listener bleibt aktiv, nachdem der Sampler abgeschlossen ist. Dies ist am besten für Themenabonnements geeignet.
JMS Punkt-zu-Punkt ¶
Dieser Sampler sendet und empfängt optional JMS-Nachrichten über Punkt-zu-Punkt-Verbindungen (Warteschlangen). Es unterscheidet sich von Pub/Sub-Nachrichten und wird im Allgemeinen zur Abwicklung von Transaktionen verwendet.
request_only wird normalerweise verwendet, um ein JMS-System zu belasten.
request_reply wird verwendet, wenn Sie die Antwortzeit eines JMS-Dienstes testen möchten, der Nachrichten verarbeitet, die an die Anforderungswarteschlange gesendet werden, da dieser Modus auf die Antwort in der von diesem Dienst gesendeten Antwortwarteschlange wartet.
browse gibt die aktuelle Warteschlangentiefe zurück, dh die Anzahl der Nachrichten in der Warteschlange.
read liest eine Nachricht aus der Warteschlange (falls vorhanden).
clear löscht die Warteschlange, dh entfernt alle Nachrichten aus der Warteschlange.
JMeter verwendet die Eigenschaften java.naming.security.[principal|credentials] – falls vorhanden – beim Erstellen der Warteschlangenverbindung. Wenn dieses Verhalten nicht erwünscht ist, setzen Sie die JMeter-Eigenschaft JMSSampler.useSecurity.properties=false

Parameter ¶
- Nur Anfrage
- sendet nur Nachrichten und überwacht keine Antworten. Als solches kann es verwendet werden, um ein System zu belasten.
- Antwort anfordern
- sendet Nachrichten und überwacht die empfangenen Antworten. Das Verhalten hängt vom Wert der JNDI-Namensantwortwarteschlange ab. Wenn JNDI Name Reply Queue einen Wert hat, wird diese Warteschlange verwendet, um die Ergebnisse zu überwachen. Der Abgleich von Anforderung und Antwort erfolgt mit der Nachrichten-ID der Anforderung und der Korrelations-ID der Antwort. Wenn die JNDI-Namensantwortwarteschlange leer ist, werden temporäre Warteschlangen für die Kommunikation zwischen dem Anforderer und dem Server verwendet. Dies unterscheidet sich stark von der festen Antwortwarteschlange. Bei temporären Warteschlangen blockiert der sendende Thread, bis die Antwortnachricht empfangen wurde. Im Request-Response- Modus benötigen Sie einen Server, der Nachrichten abhört, die an die Request-Warteschlange gesendet werden, und Antworten an die Warteschlange sendet, auf die durch message.getJMSReplyTo() verwiesen wird .
- Lesen
- liest eine Nachricht aus einer ausgehenden Warteschlange, an die keine Listener angeschlossen sind. Dies kann für Testzwecke praktisch sein. Diese Methode kann verwendet werden, wenn Sie Warteschlangen ohne Bindungsdatei verarbeiten müssen (falls die jmeter-jms-skip-jndi-Bibliothek verwendet wird), die nur mit dem JMS-Point-to-Point-Sampler funktioniert. Falls Bindungsdateien verwendet werden, kann man auch den JMS Subscriber Sampler zum Lesen aus einer Warteschlange verwenden.
- Durchsuche
- bestimmt die aktuelle Warteschlangentiefe, ohne Nachrichten aus der Warteschlange zu entfernen, und gibt die Anzahl der Nachrichten in der Warteschlange zurück.
- Klar
- löscht die Warteschlange, dh entfernt alle Nachrichten aus der Warteschlange.
- Verwenden Sie die Anforderungsnachrichten-ID
- Wenn diese Option ausgewählt ist, wird die Anfrage-JMSMessageID verwendet, andernfalls wird die Anfrage-JMSCorrelationID verwendet. Im letzteren Fall muss die Korrelations-ID in der Anfrage angegeben werden.
- Verwenden Sie die Antwortnachrichten-ID
- Wenn diese Option ausgewählt ist, wird die Antwort JMSMessageID verwendet, andernfalls wird die Antwort JMSCorrelationID verwendet.
- JMS-Korrelations-ID-Muster
- dh Anforderung und Antwort auf ihre Korrelations-IDs abgleichen => beide Kontrollkästchen deaktivieren und eine Korrelations-ID angeben.
- JMS-Nachrichten-ID-Muster
- dh Anforderungsnachrichten-ID mit Antwortkorrelations-ID abgleichen => nur "Anforderungsnachrichten-ID verwenden" auswählen.
JUnit-Anfrage ¶
- Anstatt die Testschnittstelle von JMeter zu verwenden, durchsucht es die JAR-Dateien nach Klassen, die die TestCase - Klasse von JUnit erweitern. Das schließt jede Klasse oder Unterklasse ein.
- JUnit-Test-JAR-Dateien sollten im Verzeichnis „ jmeter/lib/junit “ statt im Verzeichnis „/ lib “ abgelegt werden . Sie können auch die Eigenschaft " user.classpath " verwenden, um anzugeben, wo nach Testfallklassen gesucht werden soll .
- Der JUnit-Sampler verwendet keine Name/Wert-Paare für die Konfiguration wie die Java-Anfrage . Der Sampler geht davon aus, dass setUp und tearDown den Test korrekt konfigurieren.
- Der Sampler misst die verstrichene Zeit nur für die Testmethode und beinhaltet nicht setUp und tearDown .
- Jedes Mal, wenn die Testmethode aufgerufen wird, übergibt JMeter das Ergebnis an die Listener.
- Die Unterstützung für oneTimeSetUp und oneTimeTearDown erfolgt als Methode. Da JMeter multithreaded ist, können wir oneTimeSetUp / oneTimeTearDown nicht so aufrufen , wie es Maven tut.
- Der Sampler meldet unerwartete Ausnahmen als Fehler. Es gibt einige wichtige Unterschiede zwischen standardmäßigen JUnit-Testläufern und der Implementierung von JMeter. Anstatt für jeden Test eine neue Instanz der Klasse zu erstellen, erstellt JMeter 1 Instanz pro Sampler und verwendet sie wieder. Dies kann mit der Checkbox „ Create a new instance per sample “ geändert werden.
öffentliche Klasse meinTestfall {
öffentlich meinTestfall() {}
}
String-Konstruktor:
öffentliche Klasse meinTestfall {
öffentlich meinTestfall(Stringtext) {
super(text);
}
}
Generelle Richtlinien
Wenn Sie setUp und tearDown verwenden , stellen Sie sicher, dass die Methoden öffentlich deklariert sind. Andernfalls wird der Test möglicherweise nicht ordnungsgemäß ausgeführt.Hier sind einige allgemeine Richtlinien zum Schreiben von JUnit-Tests, damit sie gut mit JMeter funktionieren. Da JMeter multithreaded läuft, ist es wichtig, bestimmte Dinge im Auge zu behalten.
- Schreiben Sie die Methoden setUp und tearDown so, dass sie Thread-sicher sind. Dies bedeutet im Allgemeinen, dass Sie die Verwendung statischer Member vermeiden.
- Machen Sie die Testmethoden zu diskreten Arbeitseinheiten und nicht zu langen Abfolgen von Aktionen. Indem das Testverfahren auf einem diskreten Vorgang gehalten wird, wird es einfacher, Testverfahren zu kombinieren, um neue Testpläne zu erstellen.
- Vermeiden Sie es, Testmethoden voneinander abhängig zu machen. Da JMeter eine beliebige Reihenfolge von Testmethoden zulässt, unterscheidet sich das Laufzeitverhalten vom standardmäßigen JUnit-Verhalten.
- Wenn eine Testmethode konfigurierbar ist, achten Sie darauf, wo die Eigenschaften gespeichert werden. Es wird empfohlen, die Eigenschaften aus der Jar-Datei zu lesen.
- Jeder Sampler erstellt eine Instanz der Testklasse, also schreiben Sie Ihren Test so, dass die Einrichtung in oneTimeSetUp und oneTimeTearDown erfolgt .

Parameter ¶
Die folgenden JUnit4-Anmerkungen werden erkannt:
- @Prüfen
- Wird verwendet, um Testmethoden und Klassen zu finden. Die Attribute „ erwartet “ und „ Zeitüberschreitung “ werden unterstützt.
- @Vor
- wird in JUnit3 genauso behandelt wie setUp()
- @Nach
- wird in JUnit3 genauso behandelt wie tearDown()
- @VorKlasse , @NachKlasse
- als Testmethoden behandelt, sodass sie bei Bedarf unabhängig voneinander ausgeführt werden können
E- Mail-Reader-Beispiel ¶
Der Mail Reader Sampler kann E-Mail-Nachrichten mit POP3(S)- oder IMAP(S)-Protokollen lesen (und optional löschen).

Parameter ¶
Andernfalls gegen das Verzeichnis, das das Testskript (JMX-Datei) enthält.
Nachrichten werden als Subsamples des Hauptsamplers gespeichert. Mehrteilige Nachrichtenteile werden als Unterabtastwerte der Nachricht gespeichert.
Spezielle Handhabung für das „ Datei “-Protokoll:
Der Datei- JavaMail-Provider kann verwendet werden, um Rohnachrichten aus Dateien zu lesen. Das Server - Feld wird verwendet , um den Pfad zum übergeordneten Ordner des Ordners anzugeben . Einzelne Nachrichtendateien sollten unter dem Namen n.msg gespeichert werden , wobei n die Nachrichtennummer ist. Alternativ kann das Serverfeld der Name einer Datei sein, die eine einzelne Nachricht enthält. Die aktuelle Implementierung ist ziemlich einfach und hauptsächlich für Debugging-Zwecke gedacht.
Flusssteuerungsaktion (früher: Testaktion ) ¶
Dieser Sampler kann auch in Verbindung mit dem Transaction Controller nützlich sein, da er das Einfügen von Pausen ermöglicht, ohne dass ein Sample generiert werden muss. Setzen Sie für variable Verzögerungen die Pausenzeit auf Null und fügen Sie einen Timer als Kind hinzu.
Die Aktion „ Stopp “ hält den Thread oder Test an, nachdem alle laufenden Proben abgeschlossen wurden. Die Aktion „ Jetzt stoppen “ stoppt den Test, ohne auf den Abschluss der Proben zu warten; es unterbricht alle aktiven Samples. Wenn einige Threads nicht innerhalb des 5-Sekunden-Zeitlimits beendet werden, wird eine Meldung im GUI-Modus angezeigt. Sie können versuchen, den Stop- Befehl zu verwenden, um zu sehen, ob dies die Threads stoppt, aber wenn nicht, sollten Sie JMeter beenden. Im CLI-Modus wird JMeter beendet, wenn einige Threads nicht innerhalb des Zeitlimits von 5 Sekunden beendet werden.

Parameter ¶
SMTP-Sampler ¶
Der SMTP-Sampler kann E-Mail-Nachrichten über das SMTP/SMTPS-Protokoll senden. Es ist möglich, Sicherheitsprotokolle für die Verbindung (SSL und TLS) sowie die Benutzerauthentifizierung festzulegen. Wenn ein Sicherheitsprotokoll verwendet wird, erfolgt eine Überprüfung des Serverzertifikats.
Es stehen zwei Alternativen zur Handhabung dieser Überprüfung zur Verfügung:
- Vertrauen Sie allen Zertifikaten
- Dadurch wird die Überprüfung der Zertifikatskette ignoriert
- Verwenden Sie einen lokalen Truststore
- Mit dieser Option wird die Zertifikatskette anhand der lokalen Truststore-Datei validiert.

Parameter ¶
Andernfalls gegen das Verzeichnis, das das Testskript (JMX-Datei) enthält.
Betriebssystem-Prozess-Sampler ¶
Der OS Process Sampler ist ein Sampler, der zum Ausführen von Befehlen auf dem lokalen Computer verwendet werden kann.
Es sollte die Ausführung aller Befehle ermöglichen, die über die Befehlszeile ausgeführt werden können.
Die Validierung des Rückkehrcodes kann aktiviert und der erwartete Rückkehrcode angegeben werden.
Beachten Sie, dass Betriebssystem-Shells im Allgemeinen eine Befehlszeilenanalyse bereitstellen. Dies variiert je nach Betriebssystem, aber im Allgemeinen teilt die Shell Parameter auf Leerzeichen auf. Einige Shells erweitern Wildcard-Dateinamen; manche nicht. Der Zitiermechanismus variiert auch zwischen den Betriebssystemen. Der Sampler verzichtet bewusst auf Parsing oder Quote-Handling. Der Befehl und seine Parameter müssen in der Form bereitgestellt werden, die von der ausführbaren Datei erwartet wird. Dies bedeutet, dass die Sampler-Einstellungen nicht zwischen Betriebssystemen übertragbar sind.
Viele Betriebssysteme verfügen über einige integrierte Befehle, die nicht als separate ausführbare Dateien bereitgestellt werden. Beispielsweise ist der Windows DIR - Befehl Teil des Befehlsinterpreters ( CMD.EXE ). Diese integrierten Programme können nicht als eigenständige Programme ausgeführt werden, sondern müssen dem entsprechenden Befehlsinterpreter als Argumente übergeben werden.
Beispielsweise muss die Windows-Befehlszeile: DIR C:\TEMP wie folgt angegeben werden:
- Befehl:
- CMD
- Parameter 1:
- /C
- Parameter 2:
- DIR
- Parameter 3:
- C:\TEMP

Parameter ¶
MongoDB-Skript (VERALTET) ¶
Mit diesem Sampler können Sie eine Anfrage an eine MongoDB senden.
Bevor Sie dies verwenden, müssen Sie ein Element MongoDB Source Config Configuration einrichten

Parameter ¶
Schraubenanfrage ¶
Mit diesem Sampler können Sie Cypher-Abfragen über das Bolt-Protokoll ausführen.
Bevor Sie dies verwenden, müssen Sie eine Bolzenverbindungskonfiguration einrichten
Jede Anforderung verwendet eine aus dem Pool abgerufene Verbindung und gibt sie an den Pool zurück, wenn der Sampler abgeschlossen ist. Die Größe des Verbindungspools verwendet die Treibervorgaben (~100) und ist derzeit nicht konfigurierbar.
Die gemessene Antwortzeit entspricht der "vollständigen" Abfrageausführung, einschließlich sowohl der Zeit zum Ausführen der Chiffrierabfrage als auch der Zeit zum Verbrauchen der von der Datenbank zurückgesendeten Ergebnisse.

Parameter ¶
18.2 Logik-Controller ¶
Logic Controller bestimmen die Reihenfolge, in der Sampler verarbeitet werden.
Einfacher Controller ¶
Mit dem Simple Logic Controller können Sie Ihre Sampler und andere Logic Controller organisieren. Im Gegensatz zu anderen Logic Controllern bietet dieser Controller keine Funktionalität, die über die eines Speichergeräts hinausgeht.

Parameter ¶
Laden Sie dieses Beispiel herunter (siehe Abbildung 6). In diesem Beispiel haben wir einen Testplan erstellt, der zwei Ant-HTTP-Anforderungen und zwei Log4J-HTTP-Anforderungen sendet. Wir haben die Ant- und Log4J-Anforderungen gruppiert, indem wir sie in Simple Logic Controllers platziert haben. Denken Sie daran, dass der Simple Logic Controller keinen Einfluss darauf hat, wie JMeter die Controller verarbeitet, die Sie ihm hinzufügen. In diesem Beispiel sendet JMeter also die Anfragen in der folgenden Reihenfolge: Ant-Startseite, Ant-News-Seite, Log4J-Startseite, Log4J-Verlaufsseite.
Beachten Sie, dass der File Reporter so konfiguriert ist, dass er die Ergebnisse in einer Datei namens „ simple-test.dat “ im aktuellen Verzeichnis speichert.

Loop-Controller ¶
Wenn Sie Generative oder Logic Controller zu einem Loop Controller hinzufügen, durchläuft JMeter diese zusätzlich zu dem Loop-Wert, den Sie für die Thread-Gruppe angegeben haben, eine bestimmte Anzahl von Malen. Wenn Sie beispielsweise einem Loop Controller eine HTTP-Anforderung mit einer Schleifenanzahl von zwei hinzufügen und die Schleifenanzahl der Thread-Gruppe auf drei konfigurieren, sendet JMeter insgesamt 2 * 3 = 6 HTTP-Anforderungen.

Parameter ¶
Der Wert -1 entspricht dem Aktivieren des Forever -Schalters.
Sonderfall: Der im Thread Group- Element eingebettete Loop Controller verhält sich etwas anders. Sofern nicht für immer festgelegt, stoppt es den Test, nachdem die angegebene Anzahl von Iterationen durchgeführt wurde.
Laden Sie dieses Beispiel herunter (siehe Abbildung 4). In diesem Beispiel haben wir einen Testplan erstellt, der eine bestimmte HTTP-Anforderung nur einmal und eine weitere HTTP-Anforderung fünfmal sendet.

Wir haben die Thread-Gruppe für einen einzelnen Thread und einen Loop-Count-Wert von eins konfiguriert. Anstatt die Thread-Gruppe die Schleife steuern zu lassen, haben wir einen Loop-Controller verwendet. Sie können sehen, dass wir der Thread-Gruppe eine HTTP-Anforderung und einem Schleifencontroller eine weitere HTTP-Anforderung hinzugefügt haben. Wir haben den Loop Controller mit einem Loop-Count-Wert von fünf konfiguriert.
JMeter sendet die Anfragen in der folgenden Reihenfolge: Startseite, Nachrichtenseite, Nachrichtenseite, Nachrichtenseite, Nachrichtenseite und Nachrichtenseite.
Einmaliger Controller ¶
Der Once Only Logic Controller weist JMeter an, den/die darin enthaltenen Controller nur einmal pro Thread zu verarbeiten und alle Anforderungen darunter während weiterer Iterationen durch den Testplan zu übergeben.
Der Once-Only-Controller wird jetzt immer während der ersten Iteration eines übergeordneten Controllers mit Schleife ausgeführt. Wenn also der Once-Only-Controller unter einem Loop-Controller platziert wird, der für eine fünfmalige Schleife spezifiziert ist, dann wird der Once-Only-Controller nur bei der ersten Iteration durch den Loop-Controller ausgeführt (dh alle fünf Male).
Beachten Sie, dass sich der Once-Only-Controller immer noch wie zuvor erwartet verhält, wenn er einer Thread-Gruppe zugeordnet wird (wird nur einmal pro Test pro Thread ausgeführt), aber der Benutzer hat jetzt mehr Flexibilität bei der Verwendung des Once-Only-Controllers.
Für Tests, die eine Anmeldung erfordern, sollten Sie die Anmeldeanforderung in diesem Controller platzieren, da sich jeder Thread nur einmal anmelden muss, um eine Sitzung einzurichten.

Parameter ¶
Laden Sie dieses Beispiel herunter (siehe Abbildung 5). In diesem Beispiel haben wir einen Testplan mit zwei Threads erstellt, die eine HTTP-Anforderung senden. Jeder Thread sendet eine Anfrage an die Homepage, gefolgt von drei Anfragen an die Fehlerseite. Obwohl wir die Thread-Gruppe so konfiguriert haben, dass sie dreimal iteriert, sendet jeder JMeter-Thread nur eine Anfrage an die Homepage, da diese Anfrage in einem Once Only Controller lebt.

Jeder JMeter-Thread sendet die Anfragen in der folgenden Reihenfolge: Startseite, Fehlerseite, Fehlerseite, Fehlerseite.
Beachten Sie, dass der File Reporter so konfiguriert ist, dass er die Ergebnisse in einer Datei namens „ loop-test.dat “ im aktuellen Verzeichnis speichert.
Interleave-Controller ¶
Wenn Sie einem Interleave-Controller generative oder logische Controller hinzufügen, wechselt JMeter zwischen jedem der anderen Controller für jede Loop-Iteration.

Parameter ¶
Laden Sie dieses Beispiel herunter (siehe Abbildung 1). In diesem Beispiel haben wir die Thread-Gruppe so konfiguriert, dass sie zwei Threads und eine Schleifenanzahl von fünf hat, für insgesamt zehn Anforderungen pro Thread. In der folgenden Tabelle finden Sie die Reihenfolge, in der JMeter die HTTP-Anforderungen sendet.

| Schleifeniteration | Jeder JMeter-Thread sendet diese HTTP-Anforderungen |
|---|---|
| 1 | Nachrichtenseite |
| 1 | Protokollseite |
| 2 | FAQ-Seite |
| 2 | Protokollseite |
| 3 | Gump-Seite |
| 3 | Protokollseite |
| 4 | Da im Controller keine Anfragen mehr vorhanden sind, beginnt JMeter von vorne und sendet die erste HTTP-Anfrage, bei der es sich um die News-Seite handelt. |
| 4 | Protokollseite |
| 5 | FAQ-Seite |
| 5 | Protokollseite |
Laden Sie ein weiteres Beispiel herunter (siehe Abbildung 2). In diesem Beispiel haben wir die Thread-Gruppe so konfiguriert, dass sie einen einzelnen Thread und eine Schleifenanzahl von acht hat. Beachten Sie, dass der Testplan einen äußeren Interleave-Controller mit zwei darin enthaltenen Interleave-Controllern hat.

Der äußere Interleave Controller wechselt zwischen den beiden inneren. Dann wechselt jeder innere Interleave-Controller zwischen jeder der HTTP-Anforderungen. Jeder JMeter-Thread sendet die Anfragen in der folgenden Reihenfolge: Startseite, Interleaved, Fehlerseite, Interleaved, CVS-Seite, Interleaved und FAQ-Seite, Interleaved.
Beachten Sie, dass der File Reporter so konfiguriert ist, dass er die Ergebnisse in einer Datei namens „ interleave-test2.dat “ im aktuellen Verzeichnis speichert.

Wenn die beiden Interleave-Controller unter dem Haupt-Interleave-Controller stattdessen einfache Controller wären, dann wäre die Reihenfolge: Homepage, CVS-Seite, Interleaved, Bug-Seite, FAQ-Seite, Interleaved.
Wenn jedoch " Subcontroller-Blöcke ignorieren " auf dem Haupt-Interleave-Controller aktiviert wurde, wäre die Reihenfolge: Homepage, Interleaved, Bug-Seite, Interleaved, CVS-Seite, Interleaved und FAQ-Seite, Interleaved.
Zufälliger Controller ¶
Der Random Logic Controller verhält sich ähnlich wie der Interleave Controller, außer dass er seine Sub-Controller und Sampler nicht der Reihe nach durchläuft, sondern bei jedem Durchgang zufällig einen auswählt.

Parameter ¶
Controller für zufällige Reihenfolge ¶
Der Controller für zufällige Reihenfolge ähnelt einem einfachen Controller dahingehend, dass er jedes untergeordnete Element höchstens einmal ausführt, die Ausführungsreihenfolge der Knoten jedoch zufällig ist.

Parameter ¶
Durchsatzcontroller ¶
Mit dem Throughput Controller kann der Benutzer steuern, wie oft er ausgeführt wird. Es gibt zwei Modi:
- Prozent Ausführung
- totale Hinrichtungen
- Prozent Hinrichtungen
- bewirkt, dass der Controller einen bestimmten Prozentsatz der Iterationen durch den Testplan ausführt.
- Totale Hinrichtungen
- bewirkt, dass der Controller die Ausführung stoppt, nachdem eine bestimmte Anzahl von Ausführungen stattgefunden hat.

Parameter ¶
Laufzeitcontroller ¶
Der Laufzeitcontroller steuert, wie lange seine Kinder laufen. Der Controller führt seine untergeordneten Elemente aus, bis die konfigurierte (n) Laufzeit(en) überschritten sind.

Parameter ¶
Wenn Controller ¶
Mit dem If-Controller kann der Benutzer steuern, ob die darunter liegenden Testelemente (seine Kinder) ausgeführt werden oder nicht.
Standardmäßig wird die Bedingung nur einmal beim ersten Eintrag ausgewertet, aber Sie haben die Möglichkeit, sie für jedes im Controller enthaltene ausführbare Element auszuwerten.
Die beste Option (Standardeinstellung) ist, Bedingung als Variablenausdruck interpretieren zu aktivieren? , dann hast du im Bedingungsfeld 2 Möglichkeiten:
- Option 1: Verwenden Sie eine Variable, die wahr oder falsch enthält
Wenn Sie testen möchten, ob das letzte Sample erfolgreich war, können Sie ${JMeterThread.last_sample_ok} verwenden.
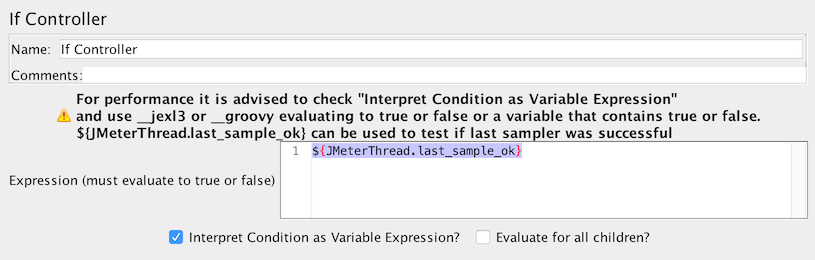
Wenn Controller Variable verwendet - Option 2: Verwenden Sie eine Funktion ( ${__jexl3()} wird empfohlen), um einen Ausdruck auszuwerten, der wahr oder falsch zurückgeben muss
Wenn Controller Ausdruck verwendet

"${meineVar}" == "\${meineVar}"
Oder verwenden Sie:
"${meineVar}" != "\${meineVar}"
um zu testen, ob eine Variable definiert und nicht null ist.


Parameter ¶
- ${COUNT} < 10
- "${VAR}" == "abcd"
Achten Sie bei der Verwendung von __groovy darauf, keine Variablenersetzung in der Zeichenfolge zu verwenden, da andernfalls bei Verwendung einer Variablen, die das Skript ändert, das Skript nicht zwischengespeichert werden kann. Holen Sie sich die Variable stattdessen mit: vars.get("myVar"). Sehen Sie sich die Groovy-Beispiele unten an.
- ${__groovy(vars.get("myVar") != "Invalid" )} (Groovy check myVar ist ungleich Invalid)
- ${__groovy(vars.get("myInt").toInteger() <=4 )} (Groovy check myInt ist kleiner oder gleich 4)
- ${__groovy(vars.get("myMissing") != null )} (Groovy prüft, ob die myMissing-Variable nicht gesetzt ist)
- ${__jexl3(${COUNT} < 10)}
- ${RESULT}
- ${JMeterThread.last_sample_ok} (überprüfen Sie, ob das letzte Beispiel erfolgreich war)
Während Controller ¶
Der While-Controller führt seine Kinder aus, bis die Bedingung " false " ist.
Mögliche Bedingungswerte:
- leer - Schleife verlassen, wenn der letzte Abtastwert in der Schleife fehlschlägt
- LAST - Schleife verlassen, wenn der letzte Abtastwert in der Schleife fehlschlägt. Wenn das letzte Sample direkt vor der Schleife fehlgeschlagen ist, geben Sie Schleife nicht ein.
- Andernfalls - Schleife verlassen (oder nicht betreten), wenn die Bedingung gleich der Zeichenfolge " false " ist
Zum Beispiel:
- ${VAR} – wobei VAR durch ein anderes Testelement auf „false “ gesetzt wird
- ${__jexl3(${C}==10)}
- ${__jexl3("${VAR2}"=="abcd")}
- ${_P(property)} - wo Eigenschaft woanders auf " false " gesetzt ist

Parameter ¶
Controller wechseln ¶
Der Switch-Controller verhält sich insofern wie der Interleave-Controller , als er eines der untergeordneten Elemente bei jeder Iteration ausführt, aber anstatt sie nacheinander auszuführen, führt der Controller das durch den Schalterwert definierte Element aus.
Wenn der Schalterwert außerhalb des zulässigen Bereichs liegt, wird das nullte Element ausgeführt, das daher als Standard für den numerischen Fall fungiert. Es führt auch das nullte Element aus, wenn der Wert die leere Zeichenfolge ist.
Wenn der Wert nicht numerisch (und nicht leer) ist, sucht der Switch Controller nach dem Element mit demselben Namen (Groß-/Kleinschreibung ist wichtig). Wenn keiner der Namen übereinstimmt, wird das Element mit dem Namen „ default “ (Groß-/Kleinschreibung nicht signifikant) ausgewählt. Wenn es keinen Standardwert gibt, wird kein Element ausgewählt und der Controller führt nichts aus.

Parameter ¶
ForEach-Controller ¶
Ein ForEach-Controller durchläuft die Werte eines Satzes verwandter Variablen. Wenn Sie Sampler (oder Controller) zu einem ForEach-Controller hinzufügen, wird jedes Sample (oder jeder Controller) einmal oder mehrmals ausgeführt, wobei die Variable während jeder Schleife einen neuen Wert hat. Die Eingabe sollte aus mehreren Variablen bestehen, die jeweils mit einem Unterstrich und einer Zahl erweitert werden. Jede solche Variable muss einen Wert haben. Wenn also die Eingabevariable beispielsweise den Namen inputVar hat, sollten die folgenden Variablen definiert worden sein:
- inputVar_1 = Wendy
- EingabeVar_2 = Karl
- inputVar_3 = peter
- inputVar_4 = john
Hinweis: Das Trennzeichen „ _ “ ist jetzt optional.
Wenn die Rückgabevariable als " returnVar " angegeben wird, wird die Sammlung von Samplern und Controllern unter dem ForEach-Controller 4 Mal hintereinander ausgeführt, wobei die Rückgabevariable die jeweiligen oben genannten Werte hat, die dann in den Samplern verwendet werden können.
Es eignet sich besonders für die Ausführung mit dem Postprozessor für reguläre Ausdrücke. Dieser kann aus den Ergebnisdaten einer vorangegangenen Anfrage die notwendigen Eingangsvariablen „erzeugen“. Durch Weglassen des Trennzeichens „ _ “ kann der ForEach-Controller verwendet werden, um die Gruppen zu durchlaufen, indem die Eingabevariable refName_g verwendet wird, und kann auch alle Gruppen in allen Übereinstimmungen durchlaufen, indem eine Eingabevariable der Form refName_${C verwendet wird }_g , wobei C eine Zählervariable ist.

Parameter ¶
Laden Sie dieses Beispiel herunter (siehe Abbildung 7). In diesem Beispiel haben wir einen Testplan erstellt, der eine bestimmte HTTP-Anforderung nur einmal sendet und eine weitere HTTP-Anforderung an jeden Link sendet, der auf der Seite zu finden ist.

Wir haben die Thread-Gruppe für einen einzelnen Thread und einen Loop-Count-Wert von eins konfiguriert. Sie können sehen, dass wir der Thread-Gruppe eine HTTP-Anforderung und dem ForEach-Controller eine weitere HTTP-Anforderung hinzugefügt haben.
Nach der ersten HTTP-Anforderung wird ein Extraktor für reguläre Ausdrücke hinzugefügt, der alle HTML-Links aus der Rückgabeseite extrahiert und in die Variable inputVar einfügt
In der ForEach-Schleife wird ein HTTP-Sampler hinzugefügt, der alle Links anfordert, die aus der ersten zurückgegebenen HTML-Seite extrahiert wurden.
Hier ist ein weiteres Beispiel , das Sie herunterladen können. Dies hat zwei reguläre Ausdrücke und ForEach-Controller. Das erste RE stimmt überein, aber das zweite stimmt nicht überein, sodass vom zweiten ForEach-Controller keine Samples ausgeführt werden

Die Thread-Gruppe hat einen einzelnen Thread und eine Schleifenanzahl von zwei.
Beispiel 1 verwendet den JavaTest-Sampler, um die Zeichenfolge " abcd " zurückzugeben.
Der Regex-Extraktor verwendet den Ausdruck (\w)\s , der einem Buchstaben gefolgt von einem Leerzeichen entspricht, und gibt den Buchstaben (nicht das Leerzeichen) zurück. Allen Übereinstimmungen wird die Zeichenfolge „ inputVar “ vorangestellt.
Der ForEach-Controller extrahiert alle Variablen mit dem Präfix „ inputVar_ “ und führt sein Beispiel aus, wobei er den Wert in der Variablen „ returnVar “ übergibt. In diesem Fall wird die Variable der Reihe nach auf die Werte „ a “, „ b “ und „ c “ gesetzt.
Der For 1 - Sampler ist ein weiterer Java-Sampler, der die Rückgabevariable „ returnVar “ als Teil des Sample-Labels und als Sampler-Daten verwendet.
Sample 2 , Regex 2 und For 2 sind fast identisch, außer dass der Regex in „ (\w)\sx “ geändert wurde, was eindeutig nicht übereinstimmt. Daher wird der For 2 Sampler nicht ausgeführt.
Modul-Controller ¶
Der Modulcontroller stellt einen Mechanismus zum Ersetzen von Testplanfragmenten in den aktuellen Testplan zur Laufzeit bereit.
Ein Testplanfragment besteht aus einem Controller und allen darin enthaltenen Testelementen (Samplern etc.). Das Fragment kann sich in jeder Thread-Gruppe befinden. Wenn sich das Fragment in einer Thread-Gruppe befindet, kann sein Controller deaktiviert werden, um zu verhindern, dass das Fragment außer vom Modul-Controller ausgeführt wird. Oder Sie können die Fragmente in einer Dummy-Thread-Gruppe speichern und die gesamte Thread-Gruppe deaktivieren.
Es können mehrere Fragmente vorhanden sein, denen jeweils eine andere Serie von Samplern zugeordnet ist. Der Modulcontroller kann dann zum einfachen Umschalten zwischen diesen mehreren Testfällen verwendet werden, indem einfach der entsprechende Controller in seinem Dropdown-Feld ausgewählt wird. Dies bietet Komfort für die schnelle und einfache Ausführung vieler alternativer Testpläne.
Ein Fragmentname besteht aus dem Controller-Namen und allen übergeordneten Namen. Zum Beispiel:
Testplan/Protokoll: JDBC/Control/Interleave Controller (Modul1)
Alle vom Module Controller verwendeten Fragmente müssen einen eindeutigen Namen haben , da der Name verwendet wird, um den Zielcontroller zu finden, wenn ein Testplan neu geladen wird. Stellen Sie aus diesem Grund am besten sicher, dass der Controller-Name von der Voreinstellung geändert wird - wie im obigen Beispiel gezeigt -, da sonst versehentlich ein Duplikat erstellt werden kann, wenn neue Elemente zum Testplan hinzugefügt werden.

Parameter ¶
Controller einschließen ¶
Der Include-Controller ist darauf ausgelegt, eine externe JMX-Datei zu verwenden. Um es zu verwenden, erstellen Sie unterhalb des Testplans ein Testfragment und fügen darunter beliebige Sampler, Controller usw. hinzu. Speichern Sie dann den Testplan. Die Datei kann jetzt als Teil anderer Testpläne eingefügt werden.
Der Einfachheit halber kann zu Debugging-Zwecken auch eine Thread-Gruppe in der externen JMX-Datei hinzugefügt werden. Ein Modulcontroller kann verwendet werden, um auf das Testfragment zu verweisen. Die Thread-Gruppe wird während des Include-Prozesses ignoriert.
Wenn der Test einen Cookie-Manager oder benutzerdefinierte Variablen verwendet, sollten diese im Testplan der obersten Ebene platziert werden, nicht in der enthaltenen Datei, da sonst nicht garantiert wird, dass sie funktionieren.
Wenn jedoch die Eigenschaft includecontroller.prefix definiert ist, wird der Inhalt verwendet, um dem Pfadnamen ein Präfix voranzustellen.
Wenn die Datei an dem durch Präfix + Dateiname angegebenen Speicherort nicht gefunden werden kann , versucht der Controller, den Dateinamen relativ zum JMX-Startverzeichnis zu öffnen .

Transaktionscontroller ¶
Der Transaktionscontroller generiert ein zusätzliches Muster, das die Gesamtzeit misst, die zum Ausführen der verschachtelten Testelemente benötigt wird.
Es gibt zwei Betriebsarten:
- zusätzliches Sample wird nach den verschachtelten Samples hinzugefügt
- zusätzliche Probe wird als übergeordnetes Element der verschachtelten Proben hinzugefügt
Die generierte Sample-Zeit beinhaltet alle Zeiten für die verschachtelten Sampler, ausgenommen standardmäßig (seit 2.11) Timer und die Verarbeitungszeit von Pre-/Post-Prozessoren, es sei denn, das Kontrollkästchen „ Dauer von Timer und Pre-Post-Prozessoren in generiertes Sample einbeziehen “ ist aktiviert. Je nach Taktauflösung kann sie etwas länger sein als die Summe der einzelnen Sampler plus Timer. Die Uhr kann ticken, nachdem der Controller die Startzeit aufgezeichnet hat, aber bevor die erste Probe beginnt. Ebenso am Ende.
Die erzeugte Stichprobe gilt nur dann als erfolgreich, wenn alle ihre Teilstichproben erfolgreich sind.
Im Parent-Modus sind die einzelnen Samples weiterhin im Tree View Listener zu sehen, erscheinen aber nicht mehr als separate Einträge in anderen Listenern. Außerdem erscheinen die Teilproben nicht in CSV-Protokolldateien, sie können jedoch in XML-Dateien gespeichert werden.

Parameter ¶
Aufnahme-Controller ¶
Der Recording Controller ist ein Platzhalter, der angibt, wo der Proxy-Server Samples aufzeichnen soll. Während des Testlaufs hat es keine Auswirkung, ähnlich wie beim einfachen Controller. Aber während der Aufzeichnung mit dem HTTP(S) Test Script Recorder werden alle aufgezeichneten Samples standardmäßig unter dem Recording Controller gespeichert.

Parameter ¶
Controller für kritische Abschnitte ¶
Der Critical Section Controller stellt sicher, dass seine untergeordneten Elemente (Sampler/Controller usw.) von nur einem Thread ausgeführt werden, da eine benannte Sperre vorgenommen wird, bevor untergeordnete Elemente des Controllers ausgeführt werden.

Die folgende Abbildung zeigt ein Beispiel für die Verwendung von Critical Section Controllern. In der Abbildung unten stellen 2 Critical Section Controller sicher, dass:
- DS2-${__threadNum} wird jeweils nur von einem Thread ausgeführt
- DS4-${__threadNum} wird jeweils nur von einem Thread ausgeführt

Parameter ¶
18.3 Zuhörer ¶
Die meisten Zuhörer erfüllen zusätzlich zum "Zuhören" der Testergebnisse mehrere Rollen. Sie bieten auch Möglichkeiten zum Anzeigen, Speichern und Lesen gespeicherter Testergebnisse.
Beachten Sie, dass Listener am Ende des Bereichs verarbeitet werden, in dem sie sich befinden.
Das Speichern und Lesen von Testergebnissen ist generisch. Die verschiedenen Listener haben ein Panel, in dem man die Datei angeben kann, in die die Ergebnisse geschrieben (oder ausgelesen) werden. Standardmäßig werden die Ergebnisse als XML-Dateien gespeichert, normalerweise mit der Erweiterung „ .jtl “. Das Speichern als CSV ist die effizienteste Option, aber weniger detailliert als XML (die andere verfügbare Option).
Listener verarbeiten keine Beispieldaten im CLI-Modus, aber die Rohdaten werden gespeichert, wenn eine Ausgabedatei konfiguriert wurde. Um die von einem CLI-Lauf generierten Daten zu analysieren, müssen Sie die Datei in den entsprechenden Listener laden.
Wenn Sie alle aktuellen Daten vor dem Laden einer neuen Datei löschen möchten, verwenden Sie vor dem Laden der Datei die Menüelemente oder .
Ergebnisse können aus Dateien im XML- oder CSV-Format gelesen werden. Beim Lesen aus CSV-Ergebnisdateien wird der Header (falls vorhanden) verwendet, um festzustellen, welche Felder vorhanden sind. Um eine Header-lose CSV-Datei korrekt zu interpretieren, müssen die entsprechenden Properties in jmeter.properties gesetzt werden .
Zuhörer können viel Speicher verwenden, wenn viele Samples vorhanden sind. Die meisten Zuhörer behalten derzeit eine Kopie von jedem Sample in ihrem Bereich, abgesehen von:
- Einfacher Datenschreiber
- BeanShell/JSR223-Listener
- Mailer-Visualizer
- Kurzbericht
Die folgenden Listener müssen nicht mehr Kopien von jedem einzelnen Sample aufbewahren. Stattdessen werden Samples mit der gleichen verstrichenen Zeit aggregiert. Es wird jetzt weniger Speicher benötigt, insbesondere wenn die meisten Samples nur ein oder zwei Sekunden dauern.
- Aggregierter Bericht
- Aggregiertes Diagramm
Verwenden Sie den Simple Data Writer und das CSV-Format, um die benötigte Speichermenge zu minimieren.
Ausführliche Informationen zum Einrichten der zu speichernden Standardelemente finden Sie in der Dokumentation zur Listener-Standardkonfiguration . Einzelheiten zum Inhalt der Ausgabedateien finden Sie im CSV-Protokollformat oder im XML-Protokollformat .
Die folgende Abbildung zeigt ein Beispiel für das Ergebnisdatei-Konfigurationsfenster

Parameter
Beispielergebnis Konfiguration speichern ¶
Listener können so konfiguriert werden, dass sie verschiedene Elemente in den Ergebnisprotokolldateien (JTL) speichern, indem Sie das Konfigurations-Popup wie unten gezeigt verwenden. Die Standardwerte sind wie in der Dokumentation Listener Default Configuration beschrieben definiert . Elemente mit ( CSV ) nach dem Namen gelten nur für das CSV-Format; Elemente mit ( XML ) gelten nur für das XML-Format. Das CSV-Format kann derzeit nicht zum Speichern von Elementen verwendet werden, die Zeilenumbrüche enthalten.
Beachten Sie, dass Cookies, Methode und der Abfragestring als Teil der Option " Sampler Data " gespeichert werden.

Diagrammergebnisse ¶
Der Graph Results-Listener generiert ein einfaches Diagramm, das alle Abtastzeiten darstellt. Am unteren Rand des Diagramms werden das aktuelle Sample (schwarz), der aktuelle Durchschnitt aller Samples (blau), die aktuelle Standardabweichung (rot) und die aktuelle Durchsatzrate (grün) in Millisekunden angezeigt.
Die Durchsatzzahl stellt die tatsächliche Anzahl der Anfragen/Minute dar, die der Server bearbeitet hat. Diese Berechnung beinhaltet alle Verzögerungen, die Sie Ihrem Test hinzugefügt haben, und die interne Verarbeitungszeit von JMeter. Der Vorteil einer solchen Berechnung besteht darin, dass diese Zahl etwas Reales darstellt - Ihr Server hat tatsächlich so viele Anfragen pro Minute verarbeitet, und Sie können die Anzahl der Threads erhöhen und/oder die Verzögerungen verringern, um den maximalen Durchsatz Ihres Servers zu ermitteln. Wenn Sie dagegen Berechnungen anstellen, die Verzögerungen und die Verarbeitung von JMeter berücksichtigen, wäre unklar, was Sie aus dieser Zahl schließen könnten.

In der folgenden Tabelle werden die Elemente des Diagramms kurz beschrieben. Weitere Einzelheiten zur genauen Bedeutung der statistischen Begriffe finden Sie im Internet - zB Wikipedia - oder in einem Statistikbuch.
- Daten - Zeichnen Sie die tatsächlichen Datenwerte auf
- Durchschnitt - Zeichnen Sie den Durchschnitt auf
- Median - Zeichnen Sie den Median (Mittelwert)
- Abweichung - Plotten Sie die Standardabweichung (ein Maß für die Abweichung)
- Durchsatz - Stellen Sie die Anzahl der Proben pro Zeiteinheit dar
Die einzelnen Zahlen am unteren Rand des Displays sind die aktuellen Werte. „ Letzte Abtastung“ ist die aktuell verstrichene Abtastzeit, die in der Grafik als „ Daten “ angezeigt wird.
Der oben links im Diagramm angezeigte Wert ist das Maximum des 90. Perzentils der Reaktionszeit.
Assertionsergebnisse ¶
Der Assertionsergebnis-Visualizer zeigt das Label jeder entnommenen Probe an. Es meldet auch Fehler bei Assertions , die Teil des Testplans sind.

Ergebnisbaum anzeigen ¶
Es gibt mehrere Möglichkeiten, die Antwort anzuzeigen, die über ein Dropdown-Feld unten im linken Bereich ausgewählt werden können.
| Renderer | Beschreibung |
|---|---|
| CSS/JQuery-Tester | Der CSS/JQuery-Tester funktioniert nur für Textantworten. Es zeigt den Klartext im oberen Bereich. Die Schaltfläche „ Test “ ermöglicht es dem Benutzer, CSS/JQuery auf das obere Bedienfeld anzuwenden, und die Ergebnisse werden im unteren Bedienfeld angezeigt. Die CSS/JQuery-Ausdrucks-Engine kann JSoup oder Jodd sein, die Syntax dieser beiden Implementierungen unterscheidet sich geringfügig. Beispielsweise liefert der Selector a[class=sectionlink] mit dem Attribut href , das auf die aktuelle JMeter-Funktionsseite angewendet wird, die folgende Ausgabe: Trefferzahl: 74 Übereinstimmung[1]=#Funktionen Match[2]=#what_can_do Übereinstimmung[3]=#wo Übereinstimmung[4]=#wie Match[5]=#function_helper Übereinstimmung[6]=#Funktionen Übereinstimmung[7]=#__regexFunktion Übereinstimmung[8]=#__regexFunction_parms Übereinstimmung[9]=#__Zähler … usw … |
| Dokumentieren | Die Dokumentenansicht zeigt den extrahierten Text aus verschiedenen Dokumenttypen wie Microsoft Office (Word, Excel, PowerPoint 97-2003, 2007-2010 (openxml), Apache OpenOffice (writer, calc, impress), HTML, gzip, jar/zip Dateien (Inhaltsliste) und einige Metadaten zu "Multimedia"-Dateien wie mp3, mp4, flv usw. Die vollständige Liste der unterstützten Formate finden Sie auf der Apache Tika-Formatseite.
Voraussetzung für die Dokumentenansicht ist das Herunterladen des
Apache Tika-Binärpakets ( tika-app-xxjar ) und das Ablegen dieses im Verzeichnis JMETER_HOME/lib .
Wenn das Dokument größer als 10 MB ist, wird es nicht angezeigt. Um dieses Limit zu ändern, setzen Sie die JMeter-Eigenschaft document.max_size (Einheit ist Byte) oder auf 0 , um das Limit zu entfernen.
|
| HTML | Die HTML-Ansicht versucht, die Antwort als HTML darzustellen. Das gerenderte HTML ist wahrscheinlich schlecht mit der Ansicht vergleichbar, die man in jedem Webbrowser erhalten würde; Es bietet jedoch eine schnelle Annäherung, die für die erste Ergebnisbewertung hilfreich ist. Bilder, Stylesheets etc. werden nicht heruntergeladen. |
| HTML (Download-Ressourcen) | Wenn die Ansichtsoption HTML (Ressourcen herunterladen) ausgewählt ist, kann der Renderer Bilder, Stylesheets usw. herunterladen, auf die durch den HTML-Code verwiesen wird.
|
| HTML-Quelle formatiert | Wenn die Option HTML-Quellformatierte Ansicht ausgewählt ist, zeigt der Renderer den von Jsoup formatierten und bereinigten HTML-Quellcode an .
|
| JSON | Die JSON-Ansicht zeigt die Antwort im Baumstil (verarbeitet auch in JavaScript eingebettetes JSON).
|
| JSON-Pfadtester | In der Ansicht JSON Path Tester können Sie Ihre JSON-PATH-Ausdrücke testen und die extrahierten Daten aus einer bestimmten Antwort anzeigen.
|
| JSON JMESPath-Tester | In der Ansicht JSON JMESPath Tester können Sie Ihre JMESPath- Ausdrücke testen und die extrahierten Daten aus einer bestimmten Antwort anzeigen.
|
| Regexp-Tester | Die Regexp Tester-Ansicht funktioniert nur für Textantworten. Es zeigt den Klartext im oberen Bereich. Die Schaltfläche „ Test “ ermöglicht es dem Benutzer, den regulären Ausdruck auf das obere Bedienfeld anzuwenden, und die Ergebnisse werden im unteren Bedienfeld angezeigt. Die Engine für reguläre Ausdrücke ist die gleiche wie die, die im Regular Expression Extractor verwendet wird. Zum Beispiel ergibt RE (JMeter\w*).* , das auf die aktuelle JMeter-Startseite angewendet wird, die folgende Ausgabe: Anzahl der Spiele: 26 Match[1][0]=JMeter - Apache JMeter</title> Übereinstimmung[1][1]=JMeter Match[2][0]=JMeter" title="JMeter" border="0"/></a> Übereinstimmung[2][1]=JMeter Match[3][0]=JMeterCommitters">Beitragende</a> Übereinstimmung[3][1]=JMeterCommitter … usw … Die erste Zahl in [] ist die Match-Nummer; die zweite Zahl ist die Gruppe. Gruppe [0] ist alles, was mit dem gesamten RE übereinstimmt. Gruppe [1] ist das, was der 1. Gruppe entspricht , dh (JMeter\w*) in diesem Fall. Siehe Abbildung 9b (unten). |
| Text |
Die standardmäßige Textansicht zeigt den gesamten in der Antwort enthaltenen Text. Beachten Sie, dass dies nur funktioniert, wenn der Inhaltstyp der Antwort als Text angesehen wird. Wenn der Inhaltstyp mit einem der folgenden beginnt, wird er als binär betrachtet, andernfalls als Text.
Bild/ Audio/ Video/ |
| XML | Die XML-Ansicht zeigt die Antwort im Baumstil. Alle DTD-Knoten oder Prolog-Knoten werden nicht im Baum angezeigt; die Antwort kann jedoch diese Knoten enthalten. Sie können mit der rechten Maustaste auf einen beliebigen Knoten klicken und alle darunter liegenden Knoten erweitern oder reduzieren.
|
| XPath-Tester | Der XPath-Tester funktioniert nur für Textantworten. Es zeigt den Klartext im oberen Bereich. Die Schaltfläche „ Test “ ermöglicht es dem Benutzer, die XPath-Abfrage auf das obere Panel anzuwenden, und die Ergebnisse werden im unteren Panel angezeigt. |
| Boundary Extractor Tester | Der Boundary Extractor Tester funktioniert nur für Textantworten. Es zeigt den Klartext im oberen Bereich. Die Schaltfläche „ Test “ ermöglicht es dem Benutzer, die Boundary Extractor-Abfrage auf das obere Panel anzuwenden, und die Ergebnisse werden im unteren Panel angezeigt. |
Automatisch scrollen? Option erlaubt die Anzeige des letzten Knotens in der Baumauswahl
Mit der Suchoption ermöglichen die meisten Ansichten auch das Durchsuchen der angezeigten Daten; das Ergebnis der Suche wird oben im Display hervorgehoben. Der folgende Screenshot der Systemsteuerung zeigt beispielsweise ein Ergebnis der Suche nach " Java ". Beachten Sie, dass die Suche auf den sichtbaren Text angewendet wird, sodass Sie möglicherweise unterschiedliche Ergebnisse erhalten, wenn Sie in den Text- und HTML-Ansichten suchen.
Hinweis: Der reguläre Ausdruck verwendet die Java-Engine (keine ORO-Engine wie der Regular Expression Extractor oder die Regexp Tester-Ansicht).
Wenn kein Inhaltstyp angegeben ist , wird der Inhalt in keinem der Antwortdatenfelder angezeigt. Sie können Antworten in einer Datei speichern verwenden, um die Daten in diesem Fall zu speichern. Beachten Sie, dass die Antwortdaten weiterhin im Probenergebnis verfügbar sind, sodass sie weiterhin mit Postprozessoren aufgerufen werden können.
Wenn die Antwortdaten größer als 200 KB sind, werden sie nicht angezeigt. Um dieses Limit zu ändern, legen Sie die JMeter-Eigenschaft view.results.tree.max_size fest . Sie können auch die gesamte Antwort in einer Datei speichern, indem Sie Antworten in einer Datei speichern verwenden .
Zusätzliche Renderer können erstellt werden. Die Klasse muss die Schnittstelle org.apache.jmeter.visualizers.ResultRenderer implementieren und/oder die abstrakte Klasse org.apache.jmeter.visualizers.SamplerResultTab erweitern , und der kompilierte Code muss für JMeter verfügbar sein (z. B. durch Hinzufügen zur lib/ ext- Verzeichnis).

Das Bedienfeld (oben) zeigt ein Beispiel für eine HTML-Anzeige.
Abbildung 9 (unten) zeigt ein Beispiel für eine XML-Anzeige.
Abbildung 9a (unten) zeigt ein Beispiel für die Anzeige eines Regexp-Testers.
Abbildung 9b (unten) zeigt ein Beispiel einer Dokumentenanzeige.



Gesamtbericht ¶
Der Durchsatz wird aus Sicht des Sampler-Targets (z. B. des entfernten Servers bei HTTP-Samples) berechnet. JMeter berücksichtigt die Gesamtzeit, in der die Anfragen generiert wurden. Wenn sich andere Sampler und Timer im selben Thread befinden, erhöhen diese die Gesamtzeit und verringern daher den Durchsatzwert. Zwei identische Sampler mit unterschiedlichen Namen haben also den halben Durchsatz von zwei Samplern mit demselben Namen. Es ist wichtig, die Probennehmernamen richtig auszuwählen, um die besten Ergebnisse aus dem Gesamtbericht zu erhalten.
Die Berechnung der Werte für den Median und die 90 %-Linie (90. Perzentil ) erfordert zusätzlichen Speicher. JMeter kombiniert jetzt Samples mit der gleichen verstrichenen Zeit, bisher wird weniger Speicher verwendet. Bei Samples, die länger als ein paar Sekunden dauern, ist es jedoch wahrscheinlich, dass weniger Samples identische Zeiten haben, in diesem Fall wird mehr Speicher benötigt. Beachten Sie, dass Sie diesen Listener später verwenden können, um eine CSV- oder XML-Ergebnisdatei neu zu laden. Dies ist die empfohlene Methode, um Leistungseinbußen zu vermeiden. Siehe Zusammenfassungsbericht für einen ähnlichen Listener, der keine einzelnen Samples speichert und daher konstanten Speicher benötigt.
- aggregat_rpt_pct1 : Standardmäßig 90. Perzentil
- aggregat_rpt_pct2 : Standardmäßig 95. Perzentil
- aggregat_rpt_pct3 : Standardmäßig 99. Perzentil
- Bezeichnung - Die Bezeichnung der Probe. Wenn „ Gruppennamen in Bezeichnung aufnehmen? “ ausgewählt ist, wird der Name der Thread-Gruppe als Präfix hinzugefügt. Dadurch können identische Etiketten aus unterschiedlichen Garngruppen bei Bedarf separat zusammengetragen werden.
- # Proben - Die Anzahl der Proben mit demselben Etikett
- Durchschnitt - Die durchschnittliche Zeit einer Reihe von Ergebnissen
- Median – Der Median ist die Zeit in der Mitte einer Reihe von Ergebnissen. 50 % der Proben brauchten nicht länger als diese Zeit; der Rest dauerte mindestens genauso lange.
- 90 %-Linie – 90 % der Proben dauerten nicht länger als diese Zeit. Die restlichen Proben dauerten mindestens so lange. ( 90. Perzentil )
- 95 %-Linie – 95 % der Proben dauerten nicht länger als diese Zeit. Die restlichen Proben dauerten mindestens so lange. ( 95. Perzentil )
- 99 % Linie - 99 % der Proben dauerten nicht länger als diese Zeit. Die restlichen Proben dauerten mindestens so lange. ( 99. Perzentil )
- Min - Die kürzeste Zeit für Proben mit demselben Etikett
- Max – Die längste Zeit für Proben mit demselben Etikett
- Fehler % – Prozentsatz der Anfragen mit Fehlern
- Durchsatz – der Durchsatz wird in Anforderungen pro Sekunde/Minute/Stunde gemessen. Die Zeiteinheit ist so gewählt, dass der angezeigte Kurs mindestens 1,0 beträgt. Wenn der Durchsatz in einer CSV-Datei gespeichert wird, wird er in Anfragen/Sekunde ausgedrückt, dh 30,0 Anfragen/Minute werden als 0,5 gespeichert.
- Empfangene KB/s – Der Durchsatz, gemessen in empfangenen Kilobyte pro Sekunde
- Gesendete KB/s – Der Durchsatz, gemessen in gesendeten Kilobyte pro Sekunde
Die Zeiten sind in Millisekunden.

Die folgende Abbildung zeigt ein Beispiel für die Auswahl des Kontrollkästchens „ Gruppennamen einbeziehen “.

Ergebnisse in Tabelle anzeigen ¶
Standardmäßig werden nur die Haupt- (Eltern-)Samples angezeigt; die Sub-Samples (Kind-Samples) werden nicht angezeigt. JMeter hat ein Kontrollkästchen „ Untergeordnete Proben? “. Wenn dies ausgewählt ist, werden die Unterproben anstelle der Hauptproben angezeigt.

Einfacher Datenschreiber ¶
Aggregierter Graph ¶

Die folgende Abbildung zeigt ein Beispiel für Einstellungen zum Zeichnen dieses Diagramms.

Parameter ¶
- Anzuzeigende Spalten: Wählen Sie die Spalte(n) aus, die im Diagramm angezeigt werden sollen.
- Rechteckfarbe: Klicken Sie auf das rechte farbige Rechteck, um ein Popup-Dialogfeld zu öffnen, um eine benutzerdefinierte Farbe für die Spalte auszuwählen.
- Vordergrundfarbe Ermöglicht das Ändern der Werttextfarbe .
- Wert Schriftart: Ermöglicht das Festlegen von Schriftarteinstellungen für den Text.
- Umrissleiste zeichnen? Um die Grenzlinie auf dem Balkendiagramm zu zeichnen oder nicht
- Nummerngruppierung anzeigen? Gruppierung der Zahlen in Y-Achsenbeschriftungen anzeigen oder nicht.
- Wertelabels vertikal? Ausrichtung der Wertebeschriftung ändern. (Standard ist horizontal)
-
Auswahl der Spaltenbeschriftung: Filtern nach Ergebnisbeschriftung. Ein regulärer Ausdruck kann verwendet werden, Beispiel: .*Transaktion.*
Bevor Sie das Diagramm anzeigen, klicken Sie auf die Schaltfläche Filter anwenden , um interne Daten zu aktualisieren.
Reaktionszeitdiagramm ¶

Die folgende Abbildung zeigt ein Beispiel für Einstellungen zum Zeichnen dieses Diagramms.

Parameter ¶
Mailer-Visualizer ¶
Der Mailer-Visualizer kann so eingerichtet werden, dass E-Mails gesendet werden, wenn ein Testlauf zu viele fehlgeschlagene Antworten vom Server erhält.

Parameter ¶
BeanShell-Listener ¶
Der BeanShell Listener ermöglicht die Verwendung von BeanShell zum Verarbeiten von Samples zum Speichern usw.
Ausführliche Informationen zur Verwendung von BeanShell finden Sie auf der BeanShell-Website.
Das Testelement unterstützt die Methoden ThreadListener und TestListener . Diese sollten in der Initialisierungsdatei definiert werden. Beispieldefinitionen finden Sie in der Datei BeanShellListeners.bshrc .

Parameter ¶
- Parameter
- Zeichenfolge, die die Parameter als einzelne Variable enthält
- bsh.args
- String-Array mit Parametern, aufgeteilt auf Leerzeichen
Vor dem Aufruf des Skripts werden einige Variablen im BeanShell-Interpreter eingerichtet:
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); - props – (JMeterProperties – class java.util.Properties ) – zB props.get("START.HMS"); props.put("PROP1","1234");
- sampleResult , prev - ( SampleResult ) - gibt Zugriff auf das vorherige SampleResult
- sampleEvent ( SampleEvent ) ermöglicht den Zugriff auf das aktuelle Beispielereignis
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
Wenn die Eigenschaft beanshell.listener.init definiert ist, wird diese zum Laden einer Initialisierungsdatei verwendet, mit der Methoden usw. zur Verwendung im BeanShell-Skript definiert werden können.
Zusammenfassender Bericht ¶
Der Durchsatz wird aus Sicht des Sampler-Targets (z. B. des entfernten Servers bei HTTP-Samples) berechnet. JMeter berücksichtigt die Gesamtzeit, in der die Anfragen generiert wurden. Wenn sich andere Sampler und Timer im selben Thread befinden, erhöhen diese die Gesamtzeit und verringern daher den Durchsatzwert. Zwei identische Sampler mit unterschiedlichen Namen haben also den halben Durchsatz von zwei Samplern mit demselben Namen. Es ist wichtig, die Probenetiketten richtig auszuwählen, um die besten Ergebnisse aus dem Bericht zu erhalten.
- Bezeichnung - Die Bezeichnung der Probe. Wenn „ Gruppennamen in Bezeichnung aufnehmen? “ ausgewählt ist, wird der Name der Thread-Gruppe als Präfix hinzugefügt. Dadurch können identische Etiketten aus unterschiedlichen Garngruppen bei Bedarf separat zusammengetragen werden.
- # Proben - Die Anzahl der Proben mit demselben Etikett
- Durchschnitt – Die durchschnittlich verstrichene Zeit einer Reihe von Ergebnissen
- Min – Die niedrigste verstrichene Zeit für die Proben mit demselben Etikett
- Max – Die längste verstrichene Zeit für die Proben mit demselben Etikett
- Std. Entwickler - die Standardabweichung der verstrichenen Zeit der Probe
- Fehler % – Prozentsatz der Anfragen mit Fehlern
- Durchsatz – der Durchsatz wird in Anforderungen pro Sekunde/Minute/Stunde gemessen. Die Zeiteinheit ist so gewählt, dass der angezeigte Kurs mindestens 1,0 beträgt . Wenn der Durchsatz in einer CSV-Datei gespeichert wird, wird er in Anfragen/Sekunde ausgedrückt, dh 30,0 Anfragen/Minute werden als 0,5 gespeichert .
- Empfangene KB/s – Der Durchsatz, gemessen in Kilobyte pro Sekunde
- Gesendet KB/s – Der Durchsatz, gemessen in Kilobyte pro Sekunde
- Durchschn. Bytes – durchschnittliche Größe der Beispielantwort in Bytes.
Die Zeiten sind in Millisekunden.

Die folgende Abbildung zeigt ein Beispiel für die Auswahl des Kontrollkästchens „ Gruppennamen einbeziehen “.

Antworten in einer Datei speichern ¶
Dieses Testelement kann beliebig im Testplan platziert werden. Für jede Probe in ihrem Geltungsbereich wird eine Datei mit den Antwortdaten erstellt. Die primäre Verwendung dafür ist das Erstellen von Funktionstests, aber es kann auch nützlich sein, wenn die Antwort zu groß ist, um im View Results Tree Listener angezeigt zu werden. Der Dateiname wird aus dem angegebenen Präfix plus einer Nummer gebildet (sofern dies nicht deaktiviert ist, siehe unten). Die Dateiendung wird, falls bekannt, aus dem Dokumenttyp gebildet. Wenn nicht bekannt, wird die Dateierweiterung auf „ unbekannt “ gesetzt'. Wenn die Nummerierung deaktiviert ist und das Hinzufügen eines Suffix deaktiviert ist, wird das Dateipräfix als vollständiger Dateiname verwendet. Dadurch kann bei Bedarf ein fester Dateiname generiert werden. Der generierte Dateiname wird in der Beispielantwort gespeichert und kann bei Bedarf in der Testprotokoll-Ausgabedatei gespeichert werden.
Das aktuelle Sample wird zuerst gespeichert, gefolgt von allen Sub-Samples (Kind-Samples). Wenn ein Variablenname angegeben wird, werden die Namen der Dateien in der Reihenfolge gespeichert, in der die Teilstichproben erscheinen. Siehe unten.

Parameter ¶
Wenn übergeordnete Ordner im Präfix nicht vorhanden sind, erstellt JMeter sie und stoppt den Test, wenn er fehlschlägt.
JSR223-Listener ¶
Der JSR223-Listener ermöglicht die Anwendung von JSR223-Skriptcode auf Beispielergebnisse.
Parameter ¶
- Parameter
- Zeichenfolge, die die Parameter als einzelne Variable enthält
- Argumente
- String-Array mit Parametern, aufgeteilt auf Leerzeichen
Vor dem Aufruf des Skripts werden einige Variablen eingerichtet. Beachten Sie, dass dies JSR223-Variablen sind - dh sie können direkt im Skript verwendet werden.
- Protokoll
- ( Logger ) - kann zum Schreiben in die Protokolldatei verwendet werden
- Etikett
- das String-Label
- Dateiname
- Name der Skriptdatei (falls vorhanden)
- Parameter
- die Parameter (als String)
- Argumente
- die Parameter als String-Array (auf Whitespace aufgeteilt)
- ctx
- ( JMeterContext ) - gibt Zugriff auf den Kontext
- var
- ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); vars.getObject("OBJ2"); - Requisiten
- (JMeterProperties - Klasse java.util.Properties ) - zB props.get("START.HMS"); props.put("PROP1","1234");
- BeispielErgebnis , vorh
- ( SampleResult ) – gewährt Zugriff auf das SampleResult
- Beispielereignis
- ( SampleEvent ) - gewährt Zugriff auf das SampleEvent
- Probenehmer
- ( Sampler )- gibt Zugriff auf den letzten Sampler
- AUS
- System.out - zB OUT.println("Nachricht")
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
Zusammenfassungsergebnisse generieren ¶
# Definieren Sie die folgende Eigenschaft, um automatisch einen Summierer mit diesem Namen zu starten # (gilt nur für den CLI-Modus) #summariser.name=Zusammenfassung # # Intervall zwischen Zusammenfassungen (in Sekunden) Standard 3 Minuten #summariser.interval=30 # # Meldungen in Logdatei schreiben #summariser.log=true # # Nachrichten an System.out schreiben #summariser.out=trueDieses Element ist hauptsächlich für Batch-Läufe (CLI) vorgesehen. Die Ausgabe sieht wie folgt aus:
Label + 16 in 0:00:12 = 1,3/s Avg: 1608 Min: 1163 Max: 2009 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label + 82 in 0:00:30 = 2,7/s Avg: 1518 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label = 98 in 0:00:42 = 2,3/s Avg: 1533 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 85 in 0:00:30 = 2,8/s Avg: 1505 Min: 1008 Max: 2005 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label = 183 in 0:01:13 = 2,5/s Avg: 1520 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 79 in 0:00:30 = 2,7/s Avg: 1578 Min: 1089 Max: 2012 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Bezeichnung = 262 in 0:01:43 = 2,6/s Durchschnitt: 1538 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 80 in 0:00:30 = 2,7/s Avg: 1531 Min: 1013 Max: 2014 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Bezeichnung = 342 in 0:02:12 = 2,6/s Durchschnitt: 1536 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 83 in 0:00:31 = 2,7/s Avg: 1512 Min: 1003 Max: 1982 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label = 425 in 0:02:43 = 2,6/s Avg: 1531 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 83 in 0:00:29 = 2,8/s Avg: 1487 Min: 1023 Max: 2013 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label = 508 in 0:03:12 = 2,6/s Durchschnitt: 1524 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 78 in 0:00:30 = 2,6/s Avg: 1594 Min: 1013 Max: 2016 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label = 586 in 0:03:43 = 2,6/s Durchschnitt: 1533 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 80 in 0:00:30 = 2,7/s Avg: 1516 Min: 1013 Max: 2005 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label = 666 in 0:04:12 = 2,6/s Avg: 1531 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 86 in 0:00:30 = 2,9/s Avg: 1449 Min: 1004 Max: 2017 Fehler: 0 (0,00 %) Aktiv: 5 Begonnen: 5 Beendet: 0 Label = 752 in 0:04:43 = 2,7/s Avg: 1522 Min: 1003 Max: 2020 Fehler: 0 (0,00 %) Label + 65 in 0:00:24 = 2,7/s Avg: 1579 Min: 1007 Max: 2003 Fehler: 0 (0,00 %) Aktiv: 0 Gestartet: 5 Beendet: 5 Label = 817 in 0:05:07 = 2,7/s Durchschnitt: 1526 Min: 1003 Max: 2020 Fehler: 0 (0,00 %)Das „ Label “ ist der Name des Elements. Das „+“ bedeutet, dass die Linie eine Delta-Linie ist, dh die Änderungen seit der letzten Ausgabe zeigt.
Das "=" bedeutet, dass die Zeile eine Summenzeile ist, dh es zeigt die laufende Summe an.
Einträge in der JMeter-Protokolldatei enthalten auch Zeitstempel. Das Beispiel „ 817 in 0:05:07 = 2,7/s “ bedeutet, dass in 5 Minuten und 7 Sekunden 817 Samples aufgezeichnet wurden, und das ergibt 2,7 Samples pro Sekunde.
Die Zeiten Avg (Durchschnitt), Min (Minimum) und Max (Maximum) werden in Millisekunden angegeben.
„ Err “ bedeutet die Anzahl der Fehler (auch in Prozent angegeben).
Die letzten beiden Zeilen erscheinen am Ende eines Tests. Sie werden nicht mit der entsprechenden Zeitgrenze synchronisiert. Beachten Sie, dass die anfänglichen und endgültigen Deltas kürzer als das Intervall sein können (im obigen Beispiel sind dies 30 Sekunden). Das erste Delta wird im Allgemeinen niedriger sein, da JMeter mit der Intervallgrenze synchronisiert. Das letzte Delta wird niedriger sein, da der Test im Allgemeinen nicht an einer genauen Intervallgrenze endet.
Das Etikett wird verwendet, um Probenergebnisse zu gruppieren. Wenn Sie also mehrere Thread-Gruppen haben und über alle zusammenfassen möchten, verwenden Sie dieselbe Bezeichnung – oder fügen Sie den Summierer zum Testplan hinzu (damit alle Thread-Gruppen im Geltungsbereich sind). Verschiedene Zusammenfassungsgruppierungen können implementiert werden, indem geeignete Bezeichnungen verwendet werden und die Zusammenfassungen zu geeigneten Teilen des Testplans hinzugefügt werden.
Dies ist kein Fehler, sondern eine Designentscheidung, die eine Zusammenfassung über Threadgruppen hinweg ermöglicht.

Parameter ¶
Visualizer für Vergleichsbehauptungen ¶

Parameter ¶
Backend-Listener ¶

Parameter ¶
Die folgenden Parameter gelten für die GraphiteBackendListenerClient- Implementierung:
Parameter ¶
Siehe auch Echtzeit-Ergebnisse für weitere Details.

Seit JMeter 3.2 eine Implementierung, die das direkte Schreiben in InfluxDB mit einem benutzerdefinierten Schema ermöglicht. Es heißt InfluxdbBackendListenerClient . Die folgenden Parameter gelten für die InfluxdbBackendListenerClient- Implementierung:
Parameter ¶
Siehe auch Echtzeitergebnisse und Influxdb-Anmerkungen in Grafana für weitere Details. Es gibt auch einen Unterabschnitt zum Konfigurieren des Listeners für InfluxDB v2 .
Seit JMeter 5.4 eine Implementierung, die alle Beispielergebnisse in InfluxDB schreibt. Es heißt InfluxDBRAwBackendListenerClient . Es ist erwähnenswert, dass dies aufgrund der Zunahme von Daten und einzelnen Schreibvorgängen sowohl von JMeter als auch von InfluxDB mehr Ressourcen verbraucht als InfluxdbBackendListenerClient . Die folgenden Parameter gelten für die InfluxDBRAwBackendListenerClient- Implementierung:
Parameter ¶
18.4 Konfigurationselemente ¶
Konfigurationselemente können verwendet werden, um Standardwerte und Variablen für die spätere Verwendung durch Probenehmer einzurichten. Beachten Sie, dass diese Elemente am Anfang des Bereichs verarbeitet werden, in dem sie gefunden werden, dh vor allen Samplern im selben Bereich.
CSV-Datensatzkonfiguration ¶
CSV Data Set Config wird verwendet, um Zeilen aus einer Datei zu lesen und sie in Variablen aufzuteilen. Sie ist einfacher zu verwenden als die Funktionen __CSVRead() und __StringFromFile() . Es eignet sich gut zum Umgang mit einer großen Anzahl von Variablen und ist auch zum Testen mit "zufälligen" und eindeutigen Werten nützlich.
Das Generieren eindeutiger Zufallswerte zur Laufzeit ist in Bezug auf CPU und Speicher teuer, also erstellen Sie die Daten einfach vor dem Test. Bei Bedarf können die "zufälligen" Daten aus der Datei in Verbindung mit einem Laufzeitparameter verwendet werden, um unterschiedliche Wertesätze aus jedem Durchlauf zu erstellen - zB durch Verkettung - was viel billiger ist, als alles zur Laufzeit zu generieren.
JMeter erlaubt das Zitieren von Werten; Dadurch kann der Wert ein Trennzeichen enthalten. Wenn „ Daten in Anführungszeichen zulassen “ aktiviert ist, kann ein Wert in doppelte Anführungszeichen gesetzt werden. Diese werden entfernt. Um doppelte Anführungszeichen in ein Feld in Anführungszeichen einzufügen, verwenden Sie zwei doppelte Anführungszeichen. Zum Beispiel:
1, "2,3", "4" "5" => 1 2,3 4 "5
JMeter unterstützt CSV-Dateien, die eine Kopfzeile haben, die die Spaltennamen definiert. Um dies zu ermöglichen, lassen Sie das Feld „ Variablennamen “ leer. Das richtige Trennzeichen muss angegeben werden.
JMeter unterstützt CSV-Dateien mit Daten in Anführungszeichen, die Zeilenumbrüche enthalten.
Standardmäßig wird die Datei nur einmal geöffnet und jeder Thread verwendet eine andere Zeile aus der Datei. Die Reihenfolge, in der Zeilen an Threads übergeben werden, hängt jedoch von der Reihenfolge ab, in der sie ausgeführt werden, die zwischen Iterationen variieren kann. Zeilen werden zu Beginn jeder Testiteration gelesen. Der Dateiname und -modus werden in der ersten Iteration aufgelöst.
Weitere Optionen finden Sie unten in der Beschreibung des Share-Modus. Wenn Sie möchten, dass jeder Thread seinen eigenen Satz von Werten hat, müssen Sie einen Satz von Dateien erstellen, eine für jeden Thread. Zum Beispiel test1.csv , test2.csv , …, test n .csv . Verwenden Sie den Dateinamen test${__threadNum}.csv und stellen Sie den " Freigabemodus " auf " Aktueller Thread ".
Als Sonderfall wird die Zeichenfolge " \t " (ohne Anführungszeichen) im Trennzeichenfeld als Tabulator behandelt.
Wenn das Dateiende ( EOF ) erreicht ist und die Option recycle true ist , beginnt das Lesen erneut mit der ersten Zeile der Datei.
Wenn die Option recycle false und stopThread false ist , werden alle Variablen auf <EOF> gesetzt, wenn das Dateiende erreicht ist. Dieser Wert kann durch Festlegen der JMeter-Eigenschaft csvdataset.eofstring geändert werden .
Wenn die Recycle-Option false und Stop Thread true ist , wird das Erreichen von EOF dazu führen, dass der Thread gestoppt wird.

Parameter ¶
- Alle Threads – (Standardeinstellung) Die Datei wird von allen Threads gemeinsam genutzt.
- Aktuelle Thread-Gruppe – jede Datei wird einmal für jede Thread-Gruppe geöffnet, in der das Element vorkommt
- Aktueller Thread - jede Datei wird für jeden Thread separat geöffnet
- Bezeichner - Alle Threads mit demselben Bezeichner teilen dieselbe Datei. Wenn Sie also beispielsweise 4 Thread-Gruppen haben, können Sie eine gemeinsame ID für zwei oder mehr Gruppen verwenden, um die Datei zwischen ihnen zu teilen. Oder Sie könnten die Thread-Nummer verwenden, um die Datei zwischen denselben Thread-Nummern in verschiedenen Thread-Gruppen freizugeben.

DNS-Cache-Manager ¶
Das DNS-Cache-Manager-Element ermöglicht das Testen von Anwendungen, die mehrere Server hinter Load Balancern (CDN usw.) haben, wenn Benutzer Inhalte von verschiedenen IPs erhalten. Standardmäßig verwendet JMeter den JVM-DNS-Cache. Aus diesem Grund wird nur ein Server aus dem Cluster belastet. Der DNS-Cache-Manager löst Namen für jeden Thread bei jeder Iteration separat auf und speichert die Ergebnisse der Auflösung in seinem internen DNS-Cache, der unabhängig von JVM- und OS-DNS-Caches ist.
Eine Zuordnung für statische Hosts kann verwendet werden, um so etwas wie die Datei /etc/hosts zu simulieren. Diese Einträge werden gegenüber dem benutzerdefinierten Resolver bevorzugt. Benutzerdefinierten DNS-Resolver verwenden muss aktiviert sein, wenn Sie diese Zuordnung verwenden möchten.
Angenommen, Sie haben einen Testserver, den Sie mit einem Namen erreichen möchten, der (noch) nicht in Ihren DNS-Servern eingerichtet ist. Für unser Beispiel wäre dies www.example.com für den Servernamen, den Sie unter der IP des Servers a123.another.example.org erreichen möchten .
Sie könnten Ihre Workstation ändern und einen Eintrag zu Ihrer /etc/hosts -Datei hinzufügen - oder dem Äquivalent für Ihr Betriebssystem, oder einen Eintrag zur statischen Host-Tabelle des DNS-Cache-Managers hinzufügen.
Sie würden www.example.com in die erste Spalte ( Host ) und a123.another.example.org in die zweite Spalte ( Hostname oder IP-Adresse ) eingeben. Wie der Name der zweiten Spalte schon sagt, könnten Sie dort sogar die IP-Adresse Ihres Testservers verwenden.
Die IP-Adresse für den Testserver wird mithilfe des benutzerdefinierten DNS-Resolvers nachgeschlagen. Wenn keine angegeben ist, wird der System-DNS-Resolver verwendet.
Jetzt können Sie www.example.com in Ihren HTTPClient4-Samplern verwenden und die Anfragen werden an a123.another.example.org gestellt, wobei alle Header auf www.example.com gesetzt sind .

Parameter ¶
HTTP-Autorisierungsmanager ¶
Mit dem Autorisierungs-Manager können Sie eine oder mehrere Benutzeranmeldungen für Webseiten angeben, die mithilfe der Serverauthentifizierung eingeschränkt sind. Sie sehen diese Art der Authentifizierung, wenn Sie Ihren Browser verwenden, um auf eine eingeschränkte Seite zuzugreifen, und Ihr Browser zeigt ein Anmeldedialogfeld an. JMeter übermittelt die Anmeldeinformationen, wenn es auf diese Art von Seite stößt.
Die Autorisierungs-Header werden möglicherweise nicht auf der Registerkarte „ Request “ des Strukturansicht -Listeners angezeigt . Die Java-Implementierung führt eine präventive Authentifizierung durch, gibt jedoch den Authorization-Header nicht zurück, wenn JMeter die Header abruft. Die Implementierung von HttpComponents (HC 4.5.X) ist seit 3.2 standardmäßig präemptiv und der Header wird angezeigt. Um dies zu deaktivieren, legen Sie die Werte wie folgt fest. In diesem Fall wird die Authentifizierung nur als Antwort auf eine Abfrage durchgeführt.
Setzen Sie in der Datei jmeter.properties httpclient4.auth.preemptive=false

Parameter ¶
- Java
- BASIC
- HttpClient 4
- BASIC , DIGEST und Kerberos
Kerberos-Konfiguration:
Um Kerberos zu konfigurieren, müssen Sie mindestens zwei JVM-Systemeigenschaften einrichten:
- -Djava.security.krb5.conf=krb5.conf
- -Djava.security.auth.login.config=jaas.conf
Sie können diese beiden Eigenschaften auch in der Datei bin/system.properties konfigurieren . Suchen Sie in den beiden Beispielkonfigurationsdateien ( krb5.conf und jaas.conf ) im JMeter -Ordner bin nach Verweisen auf weitere Dokumentation und passen Sie sie an Ihre Kerberos-Konfiguration an.
Die Delegierung von Anmeldeinformationen ist für SPNEGO standardmäßig deaktiviert. Wenn Sie es aktivieren möchten, können Sie dies tun, indem Sie die Eigenschaft kerberos.spnego.delegate_cred auf true setzen .
Beim Generieren eines SPN für die Kerberos-SPNEGO-Authentifizierung lassen IE und Firefox die Portnummer aus der URL weg. Chrome hat eine Option ( --enable-auth-negotiate-port ), um die Portnummer aufzunehmen, wenn sie von den Standardnummern ( 80 und 443 ) abweicht. Dieses Verhalten kann emuliert werden, indem die folgende JMeter-Eigenschaft wie unten festgelegt wird.
Legen Sie in jmeter.properties oder user.properties Folgendes fest:
- kerberos.spnego.strip_port=false
Kontrollen:
- Schaltfläche „ Hinzufügen “ – Fügt der Autorisierungstabelle einen Eintrag hinzu.
- Schaltfläche „ Löschen “ – Löscht den aktuell ausgewählten Tabelleneintrag.
- Schaltfläche „ Laden “ – Lädt eine zuvor gespeicherte Berechtigungstabelle und fügt die Einträge zu den vorhandenen Berechtigungstabelleneinträgen hinzu.
- Schaltfläche „ Speichern unter“ – Speichert die aktuelle Berechtigungstabelle in einer Datei.
Laden Sie dieses Beispiel herunter. In diesem Beispiel haben wir einen Testplan auf einem lokalen Server erstellt, der drei HTTP-Anforderungen sendet, von denen zwei eine Anmeldung erfordern und die andere für alle offen ist. Siehe Abbildung 10, um die Zusammensetzung unseres Testplans zu sehen. Auf unserem Server haben wir ein eingeschränktes Verzeichnis namens „ secret “, das zwei Dateien enthält, „ index.html “ und „ index2.html “. Wir haben eine Login-ID mit dem Namen „ Kevin “ erstellt, die das Passwort „ Spot “ hat. Daher haben wir in unserem Autorisierungsmanager einen Eintrag für das eingeschränkte Verzeichnis sowie einen Benutzernamen und ein Passwort erstellt (siehe Abbildung 11). Die beiden HTTP-Requests namens „ SecretPage1 “ und „ SecretPage2 “/secret/index.html " und " /secret/index2.html ". Die andere HTTP-Anfrage mit dem Namen " NoSecretPage " stellt eine Anfrage an " /index.html ".


Wenn wir den Testplan ausführen, sucht JMeter in der Autorisierungstabelle nach der angeforderten URL. Wenn die Basis-URL mit der URL übereinstimmt, leitet JMeter diese Informationen zusammen mit der Anfrage weiter.
HTTP-Cache-Manager ¶
Der HTTP-Cache-Manager wird verwendet, um HTTP-Anforderungen innerhalb seines Bereichs Caching-Funktionalität hinzuzufügen, um die Browser-Cache-Funktion zu simulieren. Jeder virtuelle Benutzerthread hat seinen eigenen Cache. Standardmäßig speichert Cache Manager unter Verwendung des LRU-Algorithmus bis zu 5000 Elemente im Cache pro Thread für virtuelle Benutzer. Verwenden Sie die Eigenschaft „ maxSize “, um diesen Wert zu ändern. Beachten Sie, dass je mehr Sie diesen Wert erhöhen, desto mehr Speicher verbraucht der HTTP-Cache-Manager. Stellen Sie daher sicher, dass Sie die JVM-Option -Xmx entsprechend anpassen.
Wenn ein Beispiel erfolgreich ist (dh den Antwortcode 2xx hat ), werden die Werte Last-Modified und Etag (und Expired , falls relevant) für die URL gespeichert. Vor der Ausführung des nächsten Beispiels prüft der Sampler, ob ein Eintrag im Cache vorhanden ist, und wenn dies der Fall ist, werden die bedingten Header „ If-Last-Modified “ und „ If-None-Match “ für die Anforderung festgelegt.
Wenn außerdem die Option " Cache-Control/Expires-Header verwenden " ausgewählt ist, wird der Cache-Control / Expires - Wert mit der aktuellen Zeit verglichen. Wenn die Anforderung eine GET -Anforderung ist und der Zeitstempel in der Zukunft liegt, kehrt der Sampler sofort zurück, ohne die URL vom Remote-Server anzufordern. Dies soll das Browserverhalten emulieren. Beachten Sie, dass, wenn der Cache-Control- Header " no-cache " ist, die Antwort als vorab abgelaufen im Cache gespeichert wird, sodass eine bedingte GET - Anforderung generiert wird. Wenn Cache-Control einen anderen Wert hat, wird die Datei " max-age" Die Ablaufoption wird verarbeitet, um die Lebensdauer des Eintrags zu berechnen. Wenn sie fehlt, wird der Ablauf-Header verwendet, wenn auch der fehlende Eintrag gemäß RFC 2616, Abschnitt 13.2.4 , unter Verwendung der Zeit der letzten Änderung und des Antwortdatums zwischengespeichert wird.

Parameter ¶
HTTP-Cookie-Manager ¶
Das Cookie-Manager-Element hat zwei Funktionen:
Erstens speichert und sendet es Cookies wie ein Webbrowser. Wenn Sie eine HTTP-Anforderung haben und die Antwort ein Cookie enthält, speichert der Cookie-Manager dieses Cookie automatisch und verwendet es für alle zukünftigen Anforderungen an diese bestimmte Website. Jeder JMeter-Thread hat seinen eigenen "Cookie-Speicherbereich". Wenn Sie also eine Website testen, die ein Cookie zum Speichern von Sitzungsinformationen verwendet, hat jeder JMeter-Thread seine eigene Sitzung. Beachten Sie, dass solche Cookies nicht in der Anzeige des Cookie-Managers erscheinen, aber mit dem View Results Tree Listener angezeigt werden können.
JMeter prüft, ob empfangene Cookies für die URL gültig sind. Das bedeutet, dass keine domainübergreifenden Cookies gespeichert werden. Wenn Sie fehlerhaftes Verhalten haben oder möchten, dass Cross-Domain-Cookies verwendet werden, definieren Sie die JMeter-Eigenschaft „ CookieManager.check.cookies=false “.
Empfangene Cookies können als JMeter-Thread-Variablen gespeichert werden. Um Cookies als Variablen zu speichern, definieren Sie die Eigenschaft " CookieManager.save.cookies=true ". Außerdem wird den Namen von Cookies das Präfix „ COOKIE_ “ vorangestellt, bevor sie gespeichert werden (dies vermeidet eine versehentliche Beschädigung lokaler Variablen). Um zum ursprünglichen Verhalten zurückzukehren, definieren Sie die Eigenschaft „ CookieManager.name.prefix= “ (ein oder mehrere Leerzeichen). Wenn aktiviert, kann der Wert eines Cookies mit dem Namen TEST als ${COOKIE_TEST} bezeichnet werden .
Zweitens können Sie dem Cookie-Manager manuell ein Cookie hinzufügen. Wenn Sie dies tun, wird das Cookie jedoch von allen JMeter-Threads geteilt.
Beachten Sie, dass solche Cookies mit einer weit in der Zukunft liegenden Ablaufzeit erstellt werden
Cookies mit Nullwerten werden standardmäßig ignoriert. Dies kann durch Festlegen der JMeter-Eigenschaft geändert werden: CookieManager.delete_null_cookies=false . Beachten Sie, dass dies auch für manuell definierte Cookies gilt – solche Cookies werden von der Anzeige entfernt, wenn sie aktualisiert wird. Beachten Sie auch, dass der Cookie-Name eindeutig sein muss – wenn ein zweites Cookie mit demselben Namen definiert wird, ersetzt es das erste.

Parameter ¶
[Hinweis: Wenn Sie eine Website mit IPv6-Adresse testen möchten, wählen Sie HC4CookieHandler (IPv6-konform)]
Die " Domain " ist der Hostname des Servers (ohne http:// ); der Port wird derzeit ignoriert.
Standardwerte für HTTP-Anforderungen ¶
Mit diesem Element können Sie Standardwerte festlegen, die Ihre HTTP-Anforderungscontroller verwenden. Wenn Sie beispielsweise einen Testplan mit 25 HTTP-Anforderungscontrollern erstellen und alle Anforderungen an denselben Server gesendet werden, können Sie ein einzelnes HTTP-Anforderungsstandardelement mit ausgefülltem Feld „Servername oder IP “ hinzufügen. Dann , lassen Sie beim Hinzufügen der 25 HTTP-Request-Controller das Feld „ Servername oder IP “ leer. Die Controller erben diesen Feldwert vom Element „HTTP Request Defaults“.


Parameter ¶
HTTP-Header-Manager ¶
Mit dem Header-Manager können Sie HTTP-Anforderungsheader hinzufügen oder überschreiben.
JMeter unterstützt jetzt mehrere Header-Manager . Die Header-Einträge werden zur Liste für den Sampler zusammengeführt. Wenn ein zusammenzuführender Eintrag mit einem vorhandenen Kopfzeilennamen übereinstimmt, ersetzt er den vorherigen Eintrag. Auf diese Weise können Sie einen Standardsatz von Kopfzeilen einrichten und Anpassungen an bestimmten Samplern vornehmen. Beachten Sie, dass ein leerer Wert für einen Header keinen vorhandenen Header entfernt, sondern nur seinen Wert ersetzt.

Parameter ¶
Laden Sie dieses Beispiel herunter. In diesem Beispiel haben wir einen Testplan erstellt, der JMeter anweist, den Standard-Anforderungsheader „ User-Agent “ zu überschreiben und stattdessen eine bestimmte Internet Explorer-Agentenzeichenfolge zu verwenden. (siehe Abbildungen 12 und 13).


Standardeinstellungen für Java-Anforderungen ¶
Mit der Komponente „Java Request Defaults“ können Sie Standardwerte für Java-Tests festlegen. Siehe die Java-Anfrage .

JDBC-Verbindungskonfiguration ¶

Parameter ¶
Wenn Sie wirklich Shared Pooling verwenden möchten (warum?), dann setzen Sie die maximale Anzahl auf die gleiche wie die Anzahl der Threads, um sicherzustellen, dass Threads nicht aufeinander warten.
Die Liste der Validierungsabfragen kann mit der Eigenschaft jdbc.config.check.query konfiguriert werden und ist standardmäßig:
- hsqldb
- wählen Sie 1 aus INFORMATION_SCHEMA.SYSTEM_USERS
- Orakel
- wählen Sie 1 aus dual
- DB2
- Wählen Sie 1 aus sysibm.sysdummy1 aus
- MySQL oder MariaDB
- wähle 1
- Microsoft SQL Server (MS JDBC-Treiber)
- wähle 1
- PostgreSQL
- wähle 1
- Ingr
- wähle 1
- Derby
- Werte 1
- H2
- wähle 1
- Feuervogel
- Wählen Sie 1 aus der rdb$-Datenbank aus
- Exasol
- wähle 1
Die Liste der vorkonfigurierten jdbc-Treiberklassen kann mit der Eigenschaft jdbc.config.jdbc.driver.class konfiguriert werden und ist standardmäßig:
- hsqldb
- org.hsqldb.jdbc.JDBCDriver
- Orakel
- oracle.jdbc.OracleDriver
- DB2
- com.ibm.db2.jcc.DB2Driver
- MySQL
- com.mysql.jdbc.Driver
- Microsoft SQL Server (MS JDBC-Treiber)
- com.microsoft.sqlserver.jdbc.SQLServerDriver oder com.microsoft.jdbc.sqlserver.SQLServerDriver
- PostgreSQL
- org.postgresql.Driver
- Ingr
- com.ingres.jdbc.IngresDriver
- Derby
- org.apache.derby.jdbc.ClientDriver
- H2
- org.h2.Treiber
- Feuervogel
- org.firebirdsql.jdbc.FBDriver
- Apache-Derby
- org.apache.derby.jdbc.ClientDriver
- MariaDB
- org.mariadb.jdbc.Driver
- SQLite
- org.sqlite.JDBC
- Sybase-AES
- net.sourceforge.jtds.jdbc.Driver
- Exasol
- com.exasol.jdbc.EXADriver
Unterschiedliche Datenbanken und JDBC-Treiber erfordern unterschiedliche JDBC-Einstellungen. Die Datenbank-URL und die JDBC-Treiberklasse werden vom Anbieter der JDBC-Implementierung definiert.
Nachfolgend sind einige mögliche Einstellungen aufgeführt. Bitte überprüfen Sie die genauen Details in der Dokumentation des JDBC-Treibers.
Wenn JMeter keinen geeigneten Treiber meldet , kann dies Folgendes bedeuten:
- Die Treiberklasse wurde nicht gefunden. In diesem Fall wird eine Protokollmeldung wie z. B. DataSourceElement: Treiber konnte nicht geladen werden: {Klassenname} java.lang.ClassNotFoundException: {Klassenname}
- Die Treiberklasse wurde gefunden, aber die Klasse unterstützt die Verbindungszeichenfolge nicht. Dies kann an einem Syntaxfehler in der Verbindungszeichenfolge liegen oder daran, dass der falsche Klassenname verwendet wurde.
Wenn der Datenbankserver nicht läuft oder nicht erreichbar ist, meldet JMeter eine java.net.ConnectException .
Nachfolgend sind einige Beispiele für Datenbanken und deren Parameter aufgeführt.
- MySQL
-
- Klasse Fahrer
- com.mysql.jdbc.Driver
- Datenbank-URL
- jdbc:mysql://host[:port]/dbname
- PostgreSQL
-
- Klasse Fahrer
- org.postgresql.Driver
- Datenbank-URL
- jdbc:postgresql:{Datenbankname}
- Orakel
-
- Klasse Fahrer
- oracle.jdbc.OracleDriver
- Datenbank-URL
- jdbc:oracle:thin:@//host:port/service ODER jdbc:oracle:thin:@(description=(address=(host={mc-name})(protocol=tcp)(port={port-no} ))(connect_data=(sid={sid})))
- Eindringen (2006)
-
- Klasse Fahrer
- ingres.jdbc.IngresDriver
- Datenbank-URL
- jdbc:ingres://host:port/db[;attr=Wert]
- Microsoft SQL Server (MS JDBC-Treiber)
-
- Klasse Fahrer
- com.microsoft.sqlserver.jdbc.SQLServerDriver
- Datenbank-URL
- jdbc:sqlserver://host:port;Datenbankname=Datenbankname
- Apache-Derby
-
- Klasse Fahrer
- org.apache.derby.jdbc.ClientDriver
- Datenbank-URL
- jdbc:derby://server[:port]/databaseName[;URLAttributes=value[;…]]
- MariaDB
-
- Klasse Fahrer
- org.mariadb.jdbc.Driver
- Datenbank-URL
- jdbc:mariadb://host[:port]/dbname[;URLAttributes=value[;…]]
- Exasol (siehe auch Dokumentation zum JDBC-Treiber )
-
- Klasse Fahrer
- com.exasol.jdbc.EXADriver
- Datenbank-URL
- jdbc:exa:host[:port][;schema=SCHEMA_NAME][;prop_x=value_x]
Keystore-Konfiguration ¶
Mit dem Keystore-Konfigurationselement können Sie konfigurieren, wie Keystore geladen wird und welche Schlüssel verwendet werden. Diese Komponente wird normalerweise in HTTPS-Szenarien verwendet, in denen Sie die Keystore-Initialisierung nicht in der Antwortzeit berücksichtigen möchten.
Um dieses Element zu verwenden, müssen Sie zunächst einen Java Key Store mit den zu testenden Client-Zertifikaten einrichten:
- Erstellen Sie Ihre Zertifikate entweder mit dem Java Keytool- Dienstprogramm oder über Ihre PKI
- Wenn Sie von PKI erstellt wurden, importieren Sie Ihre Schlüssel in Java Key Store, indem Sie sie in ein von JKS akzeptiertes Format konvertieren
- Verweisen Sie dann auf die Keystore-Datei über die beiden JVM-Eigenschaften (oder fügen Sie sie in system.properties hinzu ):
- -Djavax.net.ssl.keyStore=Pfad_zum_Schlüsselspeicher
- -Djavax.net.ssl.keyStorePassword=password_of_keystore
Um PKCS11 als Quelle für den Store zu verwenden, müssen Sie javax.net.ssl.keyStoreType auf PKCS11 und javax.net.ssl.keyStore auf NONE setzen .

Parameter ¶
- https.use.cached.ssl.context=false ist in jmeter.properties oder user.properties festgelegt
- Sie verwenden die HTTPClient 4-Implementierung für HTTP-Anforderungen
Login-Konfigurationselement ¶
Mit dem Login-Konfigurationselement können Sie Benutzernamen- und Kennworteinstellungen in Probenehmern hinzufügen oder überschreiben, die Benutzernamen und Kennwort als Teil ihrer Einrichtung verwenden.

Parameter ¶
Standardeinstellungen für LDAP-Anforderungen ¶
Mit der Komponente „LDAP-Anforderungsstandards“ können Sie Standardwerte für LDAP-Tests festlegen. Siehe LDAP-Anfrage .

Standardwerte für erweiterte LDAP-Anforderungen ¶
Mit der Komponente „Standardwerte für erweiterte LDAP-Anforderungen“ können Sie Standardwerte für erweiterte LDAP-Tests festlegen. Siehe die erweiterte LDAP-Anforderung .

TCP-Sampler-Konfiguration ¶
Die TCP-Sampler-Konfiguration stellt Standarddaten für den TCP-Sampler bereit

Parameter ¶
Benutzerdefinierte Variablen ¶
Mit dem Element „Benutzerdefinierte Variablen“ können Sie einen anfänglichen Satz von Variablen definieren , genau wie im Testplan .
UDVs sollten nicht mit Funktionen verwendet werden, die bei jedem Aufruf unterschiedliche Ergebnisse generieren. Nur das Ergebnis des ersten Funktionsaufrufs wird in der Variablen gespeichert. UDVs können jedoch mit Funktionen wie __P() verwendet werden, zum Beispiel:
HOST ${__P(host,localhost)}
Dadurch würde die Variable " HOST " so definiert, dass sie den Wert der JMeter-Eigenschaft " host " hat und standardmäßig " localhost " ist, wenn sie nicht definiert ist.
Informationen zum Definieren von Variablen während eines Testlaufs finden Sie unter Benutzerparameter . UDVs werden in der Reihenfolge verarbeitet, in der sie im Plan erscheinen, von oben nach unten.
Der Einfachheit halber wird vorgeschlagen, dass UDVs nur am Anfang einer Thread-Gruppe (oder vielleicht unter dem Testplan selbst) platziert werden.
Nachdem der Testplan und alle UDVs verarbeitet wurden, wird der resultierende Satz von Variablen in jeden Thread kopiert, um den anfänglichen Satz von Variablen bereitzustellen.
Wenn ein Laufzeitelement wie ein User Parameters Pre-Processor oder ein Regular Expression Extractor eine Variable mit demselben Namen wie eine der UDV-Variablen definiert, ersetzt dies den Anfangswert, und alle anderen Testelemente im Thread sehen den aktualisierten Wert Wert.

Parameter ¶
Zufallsvariable ¶
Das Random Variable Config Element wird verwendet, um zufällige numerische Zeichenfolgen zu generieren und sie zur späteren Verwendung in Variablen zu speichern. Es ist einfacher als die Verwendung von benutzerdefinierten Variablen zusammen mit der Funktion __Random() .
Die Ausgabevariable wird mithilfe des Zufallszahlengenerators erstellt, und dann wird die resultierende Zahl mithilfe der Formatzeichenfolge formatiert. Die Zahl wird mit der Formel minimum+Random.nextInt(maximum-minimum+1) berechnet . Random.nextInt() erfordert eine positive Ganzzahl. Das bedeutet, dass Maximum-Minimum - dh der Bereich - kleiner als 2147483647 sein muss , jedoch können die minimalen und maximalen Werte beliebig lange Werte sein, solange der Bereich in Ordnung ist.

Parameter ¶
Zähler ¶
Ermöglicht dem Benutzer, einen Zähler zu erstellen, auf den überall in der Thread-Gruppe verwiesen werden kann. Mit der Zählerkonfiguration kann der Benutzer einen Startpunkt, ein Maximum und das Inkrement konfigurieren. Der Zähler durchläuft eine Schleife vom Start bis zum Maximum und beginnt dann wieder mit dem Start und fährt so fort, bis der Test beendet ist.
Der Zähler verwendet einen Long-Wert, um den Wert zu speichern, sodass der Bereich von -2^63 bis 2^63-1 reicht .

Parameter ¶
Einfaches Konfigurationselement ¶
Mit dem einfachen Konfigurationselement können Sie beliebige Werte in Samplern hinzufügen oder überschreiben. Sie können den Namen des Werts und den Wert selbst auswählen. Obwohl einige abenteuerlustige Benutzer eine Verwendung für dieses Element finden könnten, ist es hier hauptsächlich für Entwickler als grundlegende GUI gedacht, die sie beim Entwickeln neuer JMeter-Komponenten verwenden können.

Parameter ¶
MongoDB-Quellkonfiguration (VERALTET) ¶
Sie können dann mit diesem Code über das Element MongoDBHolder auf das Objekt com.mongodb.DB in Beanshell oder JSR223 Test Elements zugreifen
com.mongodb.DB importieren;
import org.apache.jmeter.protocol.mongodb.config.MongoDBHolder;
DB db = MongoDBHolder.getDBFromSource("Wert der Eigenschaft MongoDB Source",
"Wert der Eigenschaft Datenbankname");
…

Parameter ¶
Es gibt eine maximale Zeitspanne für Wiederholungsversuche, die standardmäßig 15 Sekunden beträgt.
Dies kann nützlich sein, um zu vermeiden, dass einige Ausnahmen ausgelöst werden, wenn ein Server vorübergehend ausfällt, indem die Vorgänge blockiert werden.
Es kann auch nützlich sein, den Übergang zu einem neuen primären Knoten zu glätten (damit ein neuer primärer Knoten innerhalb der Wiederholungszeit gewählt wird).
- Bei einem Replikatsatz versucht der Treiber für diese Zeit, eine Verbindung mit dem alten primären Knoten herzustellen, anstatt sofort auf den neuen umzuschalten
- Dies verhindert nicht, dass bei Lese-/Schreibvorgängen auf dem Socket eine Ausnahme ausgelöst wird, die von der Anwendung behandelt werden muss.
Wird nur beim Aufbau einer neuen Verbindung verwendet. Socket.connect(java.net.SocketAddress, int)
Default ist 0 und bedeutet kein Timeout.
Der Standardwert ist 0 , was bedeutet, dass die Standardeinstellung 15 Sekunden verwendet wird, wenn autoConnectRetry aktiviert ist.
Der Standardwert ist 120.000 .
Standardwert ist 0 und bedeutet kein Timeout.
Standardwert ist false .
Alle weiteren Threads erhalten sofort eine Ausnahme.
Wenn beispielsweise connectionsPerHost 10 und threadsAllowedToBlockForConnectionMultiplier 5 ist , können bis zu 50 Threads auf eine Verbindung warten.
Standard ist 5 .
Wenn w , wtimeout , fsync oder j angegeben sind, wird diese Einstellung ignoriert.
Standard ist false .
Standard ist false .
Standard ist false .
Standard ist 0 .
Standard ist 0 .
Schraubenverbindungskonfiguration ¶

Parameter ¶
18.5 Behauptungen ¶
Assertionen werden verwendet, um zusätzliche Überprüfungen von Samplern durchzuführen, und werden nach jedem Sampler im gleichen Umfang verarbeitet. Um sicherzustellen, dass eine Assertion nur auf einen bestimmten Sampler angewendet wird, fügen Sie sie als untergeordnetes Element des Samplers hinzu.
Behauptungen können entweder auf die Hauptstichprobe, die Unterstichproben oder beide angewendet werden. Standardmäßig wird die Assertion nur auf das Hauptsample angewendet. Wenn die Assertion diese Option unterstützt, wird es einen Eintrag auf der GUI geben, der wie folgt aussieht:


Wenn ein Sub-Sampler fehlschlägt und die Hauptprobe erfolgreich ist, wird die Hauptprobe auf den Fehlerstatus gesetzt und ein Assertion-Ergebnis wird hinzugefügt. Wenn die JMeter-Variablenoption verwendet wird, wird davon ausgegangen, dass sie sich auf das Hauptsample bezieht, und jeder Fehler wird nur auf das Hauptsample angewendet.
Antwortzusicherung ¶
Im Bedienfeld für die Antwortzusicherung können Sie Musterzeichenfolgen hinzufügen, die mit verschiedenen Feldern der Anfrage oder Antwort verglichen werden. Die Musterzeichenfolgen sind:
- Enthält , Übereinstimmungen : Reguläre Ausdrücke im Perl5-Stil
- Equals , Substring : Nur-Text, Groß-/Kleinschreibung beachten
Eine Zusammenfassung der Mustererkennungszeichen finden Sie unter ORO Perl5 Regular Expressions.
Sie können auch auswählen, ob erwartet wird, dass die Zeichenfolgen mit der gesamten Antwort übereinstimmen , oder ob die Antwort nur das Muster enthalten soll. Für zusätzliche Flexibilität können Sie jedem Controller mehrere Zusicherungen zuordnen.
Beachten Sie, dass die Musterzeichenfolge keine einschließenden Trennzeichen enthalten sollte, dh verwenden Sie Price: \d+ und nicht /Price: \d+/ .
Standardmäßig befindet sich das Muster im mehrzeiligen Modus, was bedeutet, dass das Metazeichen „ . “ nicht mit Zeilenumbruch übereinstimmt. Im mehrzeiligen Modus stimmen " ^ " und " $ " mit dem Anfang oder Ende einer beliebigen Zeile innerhalb der Zeichenfolge überein - nicht nur mit dem Anfang und Ende der gesamten Zeichenfolge. Beachten Sie, dass \s New-Line entspricht. Auch der Fall ist von Bedeutung. Um diese Einstellungen zu überschreiben, kann man die erweiterte reguläre Ausdruckssyntax verwenden . Zum Beispiel:
- (?ich)
- Fall ignorieren
- (?s)
- behandle das Ziel als einzelne Zeile, dh " . " passt auf eine neue Zeile
- (?ist)
- beide oben
- (?i)Apfel(?-i) Pie
- passt zu „ Apfelkuchen “, aber nicht zu „ Apfelkuchen “
- (?s)Apple.+?Pie
- entspricht Apple gefolgt von Pie , das sich möglicherweise in einer nachfolgenden Zeile befindet.
- Apple(?s).+?Pie
- wie oben, aber es ist wahrscheinlich klarer, die (?s) am Anfang zu verwenden.

Parameter ¶
- Nur Hauptprobe - gilt nur für die Hauptprobe
- Nur Unterproben - gilt nur für die Unterproben
- Hauptprobe und Unterproben - gilt für beide.
- Zu verwendender JMeter-Variablenname – Die Assertion muss auf den Inhalt der benannten Variablen angewendet werden
- Textantwort – der Antworttext vom Server, dh der Hauptteil, ohne HTTP-Header.
- Anforderungsdaten – der an den Server gesendete Anforderungstext, dh der Hauptteil, ohne HTTP-Header.
- Antwortcode - z . B. 200
- Antwortnachricht - zB OK
- Antwort-Header , einschließlich Set-Cookie-Header (falls vorhanden)
- Anfrage-Header
- URL gesampelt
- Dokument (Text) - der extrahierte Text aus verschiedenen Arten von Dokumenten über Apache Tika (siehe Abschnitt View Results Tree Document View).
Der Gesamterfolg des Samples wird bestimmt, indem das Ergebnis der Assertion mit dem vorhandenen Response-Status kombiniert wird. Wenn das Kontrollkästchen „ Status ignorieren “ aktiviert ist, wird der Antwortstatus auf erfolgreich gesetzt, bevor die Assertion ausgewertet wird.
HTTP-Antworten mit Status in den Bereichen 4xx und 5xx werden normalerweise als nicht erfolgreich angesehen. Über die Checkbox „ Status ignorieren “ kann der Status erfolgreich gesetzt werden, bevor weitere Prüfungen durchgeführt werden. Beachten Sie, dass dadurch alle vorherigen Behauptungsfehler gelöscht werden, stellen Sie also sicher, dass dies nur für die erste Behauptung festgelegt wird.- Contains – true, wenn der Text das reguläre Ausdrucksmuster enthält
- Übereinstimmungen – wahr, wenn der gesamte Text mit dem regulären Ausdrucksmuster übereinstimmt
- Gleich - wahr, wenn der gesamte Text gleich der Musterzeichenfolge ist (Groß-/Kleinschreibung beachten)
- Teilzeichenfolge – wahr, wenn der Text die Musterzeichenfolge enthält (Groß-/Kleinschreibung beachten)
Das Muster ist ein regulärer Ausdruck im Perl5-Stil, jedoch ohne die einschließenden Klammern.




Dauerzusicherung ¶
Die Duration Assertion testet, ob jede Antwort innerhalb einer bestimmten Zeit empfangen wurde. Jede Antwort, die länger als die angegebene Anzahl von Millisekunden (vom Benutzer angegeben) dauert, wird als fehlgeschlagene Antwort markiert.

Parameter ¶
Größenzusage ¶
Die Größenzusicherung testet, ob jede Antwort die richtige Anzahl von Bytes enthält. Sie können angeben, dass die Größe gleich, größer, kleiner oder ungleich einer bestimmten Anzahl von Bytes sein soll.

Parameter ¶
- Nur Hauptprobe - Behauptung gilt nur für die Hauptprobe
- Nur Unterstichproben – Die Behauptung gilt nur für die Unterstichproben
- Hauptprobe und Unterproben - Aussage gilt für beide.
- Zu verwendender JMeter-Variablenname – Die Assertion muss auf den Inhalt der benannten Variablen angewendet werden
XML-Assertion ¶
Die XML-Assertion testet, ob die Antwortdaten aus einem formal korrekten XML-Dokument bestehen. Es validiert das XML nicht auf der Grundlage einer DTD oder eines Schemas oder führt eine weitere Validierung durch.

Parameter ¶
BeanShell-Assertion ¶
Die BeanShell-Assertion ermöglicht es dem Benutzer, die Assertion-Überprüfung mit einem BeanShell-Skript durchzuführen.
Ausführliche Informationen zur Verwendung von BeanShell finden Sie auf der BeanShell-Website.
Beachten Sie, dass für jedes unabhängige Vorkommen der Assertion in jedem Thread in einem Testskript ein anderer Interpreter verwendet wird, aber der gleiche Interpreter für nachfolgende Aufrufe verwendet wird. Das bedeutet, dass Variablen über Aufrufe der Assertion hinweg bestehen bleiben.
Alle Assertionen werden vom gleichen Thread wie der Sampler aufgerufen.
Wenn die Eigenschaft „ beanshell.assertion.init “ definiert ist, wird sie als Name einer Quelldatei an den Interpreter übergeben. Dies kann verwendet werden, um allgemeine Methoden und Variablen zu definieren. Es gibt eine Beispiel-Init-Datei im bin - Verzeichnis: BeanShellAssertion.bshrc
Das Testelement unterstützt die Methoden ThreadListener und TestListener . Diese sollten in der Initialisierungsdatei definiert werden. Beispieldefinitionen finden Sie in der Datei BeanShellListeners.bshrc .

Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- bsh.args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Es gibt ein Beispielskript, das Sie ausprobieren können.
Vor dem Aufruf des Skripts werden einige Variablen im BeanShell-Interpreter eingerichtet. Dies sind Zeichenfolgen, sofern nicht anders angegeben:
- log - das Logger -Objekt. (zB) log.warn("Nachricht"[,Throwable])
- SampleResult , prev - das SampleResult- Objekt; lesen Schreiben
- Antwort - das Antwortobjekt; lesen Schreiben
- Fehler - boolesch; lesen Schreiben; Wird verwendet, um den Assertion-Status festzulegen
- Fehlernachricht - Zeichenfolge; lesen Schreiben; Wird verwendet, um die Assertion-Nachricht festzulegen
- ResponseData - der Antworttext (Byte [])
- ResponseCode - zB 200
- ResponseMessage - zB OK
- ResponseHeaders – enthält die HTTP-Header
- RequestHeaders – enthält die an den Server gesendeten HTTP-Header
- Probenetikett
- SamplerData - Daten, die an den Server gesendet wurden
- ctx - JMeterContext
-
vars - JMeterVariables - zB
vars.get("VAR1"); vars.put("VAR2","Wert"); vars.putObject("OBJ1",neues Objekt()); -
Requisiten - JMeterProperties (Klasse java.util.Properties ) - zB
props.get("START.HMS"); props.put("PROP1","1234");
Die folgenden Methoden des Response-Objekts können nützlich sein:
- setStopThread(boolesch)
- setStopTest(boolesch)
- Zeichenfolge getSampleLabel()
- setSampleLabel(String)
MD5Hex-Assertion ¶
Die MD5Hex-Assertion ermöglicht es dem Benutzer, den MD5-Hash der Antwortdaten zu überprüfen.

Parameter ¶
HTML-Assertion ¶
Die HTML-Assertion ermöglicht es dem Benutzer, die HTML-Syntax der Antwortdaten mit JTidy zu überprüfen.

Parameter ¶
XPath-Assertion ¶
Die XPath-Assertion testet ein Dokument auf Wohlgeformtheit, hat die Möglichkeit, gegen eine DTD zu validieren oder das Dokument durch JTidy zu schicken und auf einen XPath zu testen. Wenn dieser XPath existiert, ist die Behauptung wahr. Die Verwendung von " / " passt zu jedem wohlgeformten Dokument und ist der Standard-XPath-Ausdruck. Die Assertion unterstützt auch boolesche Ausdrücke wie " count(//*error)=2 ". Weitere Informationen zu XPath finden Sie unter http://www.w3.org/TR/xpath .
Einige Beispielausdrücke:- //title[text()='Text to match'] - passt <title>Text to match</title> irgendwo in der Antwort an
- /title[text()='Text to match'] - Gleicht <title>Text to match</title> auf Stammebene in der Antwort ab

Parameter ¶
Als Umgehung für Namespace-Einschränkungen des Xalan XPath-Parsers (Implementierung, auf der JMeter basiert) müssen Sie:
- Stellen Sie eine Eigenschaftendatei bereit (wenn Ihre Datei beispielsweise namespaces.properties heißt ), die Zuordnungen für die Namespace-Präfixe enthält:
prefix1=http\://foo.apache.org prefix2=http\://toto.apache.org …
- Verweisen Sie auf diese Datei in der Datei user.properties mit der Eigenschaft:
xpath.namespace.config=Namespaces.Eigenschaften
XPath2-Assertion ¶
Die XPath2-Assertion testet ein Dokument auf Wohlgeformtheit. Die Verwendung von " / " passt zu jedem wohlgeformten Dokument und ist der Standard-XPath2-Ausdruck. Die Assertion unterstützt auch boolesche Ausdrücke wie " count(//*error)=2 ".
Einige Beispielausdrücke:- //title[text()='Text to match'] - passt <title>Text to match</title> irgendwo in der Antwort an
- /title[text()='Text to match'] - Gleicht <title>Text to match</title> auf Stammebene in der Antwort ab
Parameter ¶
XML-Schema-Assertion ¶
Die XML-Schema-Assertion ermöglicht dem Benutzer, eine Antwort anhand eines XML-Schemas zu validieren.

Parameter ¶
JSR223-Assertion ¶
Die JSR223-Assertion ermöglicht die Verwendung von JSR223-Skriptcode, um den Status des vorherigen Beispiels zu überprüfen.
Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Die folgenden Variablen werden für die Verwendung durch das Skript eingerichtet:
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- Label - das String-Label
- Dateiname - der Name der Skriptdatei (falls vorhanden)
- Parameter - die Parameter (als String)
- args - die Parameter als String-Array (auf Whitespace aufgeteilt)
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); vars.getObject("OBJ2"); -
Requisiten - (JMeterProperties - Klasse java.util.Properties ) - zB
props.get("START.HMS"); props.put("PROP1","1234"); - SampleResult , prev - ( SampleResult ) - gibt Zugriff auf das vorherige SampleResult (falls vorhanden)
- sampler - ( Sampler ) - gibt Zugriff auf den aktuellen Sampler
- OUT - System.out - zB OUT.println("Nachricht")
- AssertionResult – ( AssertionResult ) – das Assertion-Ergebnis
Das Skript kann verschiedene Aspekte des SampleResult überprüfen . Wenn ein Fehler erkannt wird, sollte das Skript AssertionResult.setFailureMessage("message") und AssertionResult.setFailure(true) verwenden .
Weitere Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
Behauptung vergleichen ¶

Parameter ¶
SMIME-Assertion ¶
- bcmail-xxx.jar (BouncyCastle SMIME/CMS)
- bcprov-xxx.jar (BouncyCastle-Anbieter)
Wenn Sie den Mail Reader Sampler verwenden , stellen Sie bitte sicher, dass Sie " Nachricht mit MIME (roh) speichern" auswählen, da die Assertion die Nachricht sonst nicht korrekt verarbeiten kann.

Parameter ¶
JSON-Assertion ¶
Mit dieser Komponente können Sie Validierungen von JSON-Dokumenten durchführen. Zuerst analysiert es den JSON und schlägt fehl, wenn die Daten nicht JSON sind. Zweitens wird nach dem angegebenen Pfad gesucht, wobei die Syntax von Jayway JsonPath 1.2.0 verwendet wird . Wenn der Pfad nicht gefunden wird, schlägt er fehl. Drittens, wenn der JSON-Pfad im Dokument gefunden wurde und eine Validierung anhand des erwarteten Werts angefordert wurde, wird eine Validierung durchgeführt. Für den Nullwert gibt es ein spezielles Kontrollkästchen in der GUI. Beachten Sie, dass, wenn der Pfad ein Array-Objekt zurückgibt, es iteriert wird und wenn der erwartete Wert gefunden wird, die Assertion erfolgreich ist. Um ein leeres Array zu validieren, verwenden Sie []Schnur. Wenn Patch ein Dictionary-Objekt zurückgibt, wird es vor dem Vergleich in eine Zeichenfolge konvertiert.

Parameter ¶
JSON JMESPath-Assertion ¶
Mit dieser Komponente können Sie mithilfe von JMESPath eine Assertion für den Inhalt von JSON-Dokumenten durchführen . Zuerst analysiert es den JSON und schlägt fehl, wenn die Daten nicht JSON sind.
Zweitens wird unter Verwendung der JMESPath-Syntax nach dem angegebenen Pfad gesucht.
Wenn der Pfad nicht gefunden wird, schlägt er fehl.
Drittens, wenn der JMES-Pfad im Dokument gefunden wurde und eine Validierung gegen den erwarteten Wert angefordert wurde, wird diese zusätzliche Prüfung durchgeführt. Wenn Sie auf Nichtigkeit prüfen möchten, verwenden Sie das Kontrollkästchen Null erwarten .
Beachten Sie, dass der Pfad nicht null sein darf, da der Ausdruck JMESPath nicht kompiliert wird und ein Fehler auftritt. Auch wenn Sie eine leere oder null Antwort erwarten, müssen Sie einen gültigen JMESPath-Ausdruck einfügen.

Parameter ¶
18.6 Timer ¶
Sie können einen Multiplikationsfaktor auf die von Random Timer berechneten Ruheverzögerungen anwenden, indem Sie die Eigenschaft timer.factor=float number festlegen , wobei float number eine positive Dezimalzahl ist.
JMeter multipliziert diesen Faktor mit der berechneten Schlafverzögerung. Diese Funktion kann verwendet werden von:
Timer werden nur in Verbindung mit einem Sampler verarbeitet. Ein Timer, der sich nicht im selben Bereich wie ein Sampler befindet, wird überhaupt nicht verarbeitet.
Um einen Timer auf einen einzelnen Sampler anzuwenden, fügen Sie den Timer als untergeordnetes Element des Samplers hinzu. Der Timer wird angewendet, bevor der Sampler ausgeführt wird. Um einen Timer nach einem Sampler anzuwenden, fügen Sie ihn entweder dem nächsten Sampler hinzu oder fügen Sie ihn als untergeordnetes Element eines Flow Control Action Samplers hinzu.
Konstanter Timer ¶
Wenn Sie möchten, dass jeder Thread zwischen den Anforderungen gleich lang pausiert, verwenden Sie diesen Timer.

Parameter ¶
Gaußscher Zufallstimer ¶
Dieser Zeitgeber hält jede Thread-Anforderung für eine zufällige Zeitspanne an, wobei die meisten Zeitintervalle in der Nähe eines bestimmten Werts liegen. Die Gesamtverzögerung ist die Summe aus dem Wert der Gaußschen Verteilung (mit Mittelwert 0,0 und Standardabweichung 1,0 ) mal dem von Ihnen angegebenen Abweichungswert und dem Offsetwert. Eine andere Möglichkeit, es zu erklären, in Gaußian Random Timer hat die Variation um einen konstanten Offset eine Gaußsche Kurvenverteilung.

Parameter ¶
Einheitlicher Zufallstimer ¶
Dieser Zeitgeber hält jede Thread-Anforderung für eine zufällige Zeitspanne an, wobei jedes Zeitintervall die gleiche Auftrittswahrscheinlichkeit hat. Die Gesamtverzögerung ist die Summe aus dem Zufallswert und dem Offset-Wert.

Parameter ¶
Timer für konstanten Durchsatz ¶
Dieser Timer führt variable Pausen ein, die berechnet werden, um den Gesamtdurchsatz (in Bezug auf Proben pro Minute) so nah wie möglich an einer bestimmten Zahl zu halten. Natürlich wird der Durchsatz geringer, wenn der Server nicht in der Lage ist, damit umzugehen, oder wenn andere Timer oder zeitraubende Testelemente dies verhindern.
Hinweis: Obwohl der Timer als Constant Throughput Timer bezeichnet wird, muss der Durchsatzwert nicht konstant sein. Er kann in Form einer Variablen oder eines Funktionsaufrufs definiert werden, und der Wert kann während eines Tests geändert werden. Der Wert kann auf verschiedene Arten geändert werden:
- über eine Zählervariable
- Verwenden einer __jexl3 , __groovy Funktion, um einen sich ändernden Wert bereitzustellen
- Verwenden des Remote-BeanShell-Servers zum Ändern einer JMeter-Eigenschaft
Weitere Einzelheiten finden Sie unter Best Practices .

Parameter ¶
- nur dieser Thread - jeder Thread versucht, den Zieldurchsatz aufrechtzuerhalten. Der Gesamtdurchsatz ist proportional zur Anzahl aktiver Threads.
- alle aktiven Threads in der aktuellen Thread-Gruppe – der Zieldurchsatz wird auf alle aktiven Threads in der Gruppe aufgeteilt. Jeder Thread wird je nach Bedarf verzögert, je nachdem, wann er zuletzt ausgeführt wurde.
- alle aktiven Threads – der Zieldurchsatz wird auf alle aktiven Threads in allen Thread-Gruppen aufgeteilt. Jeder Thread wird je nach Bedarf verzögert, je nachdem, wann er zuletzt ausgeführt wurde. In diesem Fall benötigt jede andere Thread-Gruppe einen Zeitgeber für konstanten Durchsatz mit denselben Einstellungen.
- alle aktiven Threads in der aktuellen Thread-Gruppe (gemeinsam genutzt) – wie oben, aber jeder Thread wird basierend darauf verzögert, wann ein Thread in der Gruppe zuletzt ausgeführt wurde.
- alle aktiven Threads (gemeinsam) - wie oben; Jeder Thread wird basierend darauf verzögert, wann ein Thread zuletzt ausgeführt wurde.
Die gemeinsam genutzten und nicht gemeinsam genutzten Algorithmen zielen beide darauf ab, den gewünschten Durchsatz zu erzeugen, und werden ähnliche Ergebnisse erzeugen.
Der gemeinsam genutzte Algorithmus sollte eine genauere Gesamttransaktionsrate generieren.
Der nicht gemeinsam genutzte Algorithmus sollte eine gleichmäßigere Verteilung von Transaktionen über Threads hinweg erzeugen.
Präziser Durchsatz-Timer ¶
Dieser Timer führt variable Pausen ein, die berechnet werden, um den Gesamtdurchsatz (z. B. in Bezug auf Proben pro Minute) so nah wie möglich an einer bestimmten Zahl zu halten. Natürlich wird der Durchsatz geringer, wenn der Server nicht in der Lage ist, damit umzugehen, oder wenn andere Timer, oder nicht genügend Threads oder zeitaufwändige Testelemente dies verhindern.
Obwohl der Timer als Precise Throughput Timer bezeichnet wird, zielt er nicht darauf ab, während des Tests in Intervallen von einer Sekunde genau dieselbe Anzahl von Abtastungen zu erzeugen.
Der Timer funktioniert am besten für Raten unter 36.000 Anfragen/Stunde, Ihre Laufleistung kann jedoch variieren (siehe Abschnitt Überwachung unten, wenn Ihre Ziele sehr unterschiedlich sind).
Beste Position eines Precise Throughput Timers in einem Testplan
Wie Sie vielleicht wissen, werden die Timer von allen Geschwistern und ihren untergeordneten Elementen geerbt. Aus diesem Grund ist einer der besten Orte für Precise Throughput Timer unter dem ersten Element in einer Testschleife. Sie könnten beispielsweise am Anfang einen Dummy-Sampler hinzufügen und den Timer unter diesem Dummy-Sampler platzieren
Zeitplan erstellt
Präziser Durchsatz-Timer modelliert den Poisson-Ankunftszeitplan . Dieser Zeitplan kommt oft im wirklichen Leben vor, daher ist es sinnvoll, ihn für Lasttests zu verwenden. Beispielsweise kann es natürlich vorkommen, dass nahe beieinander liegende Samples generiert werden, wodurch Parallelitätsprobleme aufgedeckt werden können. Selbst wenn es Ihnen gelingt, Poisson-Ankünfte mit Poisson Random Timer zu generieren , wäre dies anfällig für die unten aufgeführten Probleme. Beispielsweise können echte Poisson-Ankünfte eine unendlich lange Pause haben, und das ist für Lasttests nicht praktikabel. Beispielsweise könnten "normale" Poisson-Ankünfte mit einer Rate von 1 pro Sekunde zu 50 Abtastungen über einen 60 Sekunden langen Test führen.
Constant Throughput Timer konvergiert zur angegebenen Rate, erzeugt jedoch in der Regel Samples in gleichmäßigen Intervallen.
Hochlauf und Anlaufspitze
Sie könnten „Ramp-up“ oder ähnliche Ansätze verwenden, um eine Spitze beim Teststart zu vermeiden. Wenn Sie beispielsweise die Thread-Gruppe mit 100 Threads konfigurieren und die Ramp-up-Periode auf 0 (oder auf eine kleine Zahl) setzen, würden alle Threads gleichzeitig starten und es würde eine unerwünschte Lastspitze erzeugen . Wenn Sie Ramp-up Period zu hoch einstellen, kann es außerdem dazu führen, dass ganz am Anfang " zu wenige " Threads verfügbar sind, um die erforderliche Last zu erreichen.
Der Precise Throughput Timer plant die Ausführung auf zufällige Weise, sodass er zur Erzeugung einer konstanten Last verwendet werden kann, und es wird empfohlen, sowohl Ramp-up Period als auch Delay auf 0 zu setzen .
Mehrere Thread-Gruppen beginnen gleichzeitig
Eine Variation des Ramp-up- Problems kann auftreten, wenn der Testplan mehrere Thread-Gruppen enthält . Um dieses Problem abzumildern, fügt man normalerweise jeder Thread-Gruppe eine "zufällige" Verzögerung hinzu, sodass Threads zu unterschiedlichen Zeiten starten.
Precise Throughput Timer vermeidet dieses Problem, da es die Ausführung auf zufällige Weise plant. Sie müssen keine zusätzlichen zufälligen Verzögerungen hinzufügen, um Startspitzen abzumildern
Anzahl der Iterationen pro Stunde
Eine der grundlegenden Anforderungen besteht darin, N Proben pro M Minuten auszugeben. Lassen Sie es 60 Iterationen pro Stunde sein. Geschäftskunden würden es nicht verstehen, wenn Sie Lasttest-Ergebnisse mit 57 Ausführungen melden, „nur weil das Zufallsprinzip zufällig war“. Um 60 Iterationen pro Stunde zu generieren, müssen Sie wie folgt konfigurieren (andere Parameter können auf ihren Standardwerten belassen werden)
- Zieldurchsatz (Proben) : 60
- Durchlaufzeit (Sekunden) : 3600
- Testdauer (Sekunden) : 3600
Die ersten beiden Optionen legen den Durchsatz fest. Auch wenn 60/3600, 30/1800 und 120/7200 genau das gleiche Lastniveau darstellen, wählen Sie dasjenige aus, das die Geschäftsanforderungen besser darstellt. Wenn beispielsweise "60 Proben pro Stunde" getestet werden sollen, stellen Sie 60/3600 ein. Wenn "1 Probe pro Minute" getestet werden soll, stellen Sie 1/60 ein.
Die Testdauer (Sekunden) ist vorhanden, damit der Timer eine genaue Anzahl von Proben für eine bestimmte Testdauer sicherstellt. Precise Throughput Timer erstellt einen Zeitplan für die Proben beim Teststart. Wenn Sie beispielsweise einen 5-Minuten-Test mit einem Durchsatz von 60 pro Stunde durchführen möchten, würden Sie die Testdauer (Sekunden) auf 300 festlegen. Dies ermöglicht eine unternehmensfreundliche Konfiguration des Durchsatzes. Hinweis: Die Testdauer (Sekunden) begrenzt die Testdauer nicht . Es ist nur ein Hinweis für den Timer.
Anzahl der Threads und Bedenkzeiten
Einer der häufigsten Fallstricke besteht darin, die Anzahl der Threads und die Bedenkzeiten anzupassen, um am Ende den gewünschten Durchsatz zu erzielen. Auch wenn es funktionieren könnte, führt dieser Ansatz dazu, dass viel Zeit für die Testläufe aufgewendet wird. Möglicherweise müssen Threads und Verzögerungen erneut angepasst werden, wenn eine neue Anwendungsversion eintrifft.
Der präzise Durchsatz-Timer ermöglicht es, ein Durchsatzziel festzulegen und es zu erreichen, unabhängig davon, wie gut die Anwendung funktioniert. Dazu erstellt Precise Throughput Timer beim Teststart einen Zeitplan und verwendet diesen Zeitplan dann zum Freigeben von Threads. Der Hauptgrund für die Bedenkzeiten und die Anzahl der Threads sollten geschäftliche Anforderungen sein, nicht der Wunsch, den Durchsatz irgendwie anzupassen.
Zum Beispiel, wenn Ihre Anwendung von Supporttechnikern in einem Callcenter verwendet wird. Angenommen, es gibt 2 Techniker im Callcenter und der angestrebte Durchsatz beträgt 1 Techniker pro Minute. Angenommen, der Techniker braucht 4 Minuten, um die Webseite zu lesen und zu überprüfen. Für diesen Fall sollten Sie 2 Threads in der Gruppe festlegen, 4 Minuten für Denkzeitverzögerungen verwenden und 1 pro Minute in Precise Throughput Timer angeben . Natürlich würde dies etwa 2 Proben/4 Minuten = 0,5 pro Minute ergeben, und das Ergebnis eines solchen Tests bedeutet „Sie brauchen mehr Support-Techniker in einem Callcenter“ oder „Sie müssen die Zeit reduzieren, die ein Techniker benötigt, um eine Aufgabe zu erfüllen ".
Testen niedriger Raten und wiederholbarer Tests
Das Testen mit niedrigen Raten (z. B. 60 pro Stunde) erfordert die Kenntnis des gewünschten Testprofils. Wenn Sie beispielsweise Last in gleichmäßigen Intervallen (z. B. 60 Sekunden dazwischen) einspeisen müssen, sollten Sie besser Constant Throughput Timer verwenden . Wenn Sie jedoch einen randomisierten Zeitplan benötigen (z. B. um echte Benutzer zu modellieren, die Berichte ausführen), dann ist Precise Throughput Timer Ihr Freund.
Beim Vergleich der Ergebnisse mehrerer Belastungstests ist es hilfreich, genau dasselbe Testprofil wiederholen zu können. Wenn zum Beispiel Aktion X (z. B. "Gewinnbericht") nach 5 Minuten nach Teststart aufgerufen wird, wäre es schön, dieses Muster für nachfolgende Testausführungen zu replizieren. Die Replikation des gleichen Lastmusters vereinfacht die Analyse der Testergebnisse (z. B. CPU%-Diagramm).
Random Seed (Änderung von 0 auf Random) ermöglicht die Steuerung des Seed-Werts, der von Precise Throughput Timer verwendet wird . Standardmäßig wird es mit 0 initialisiert , was bedeutet, dass für jede Testausführung ein zufälliger Seed verwendet wird. Wenn Sie ein wiederholbares Lademuster benötigen, ändern Sie Random Seed in einen zufälligen Wert. Der allgemeine Rat lautet, einen Seed ungleich Null zu verwenden, und „0 by default“ ist eine Implementierungsgrenze.
Hinweis: Wenn Sie mehrere Thread-Gruppen mit denselben Durchsatzraten und demselben Seed ungleich Null verwenden, kann dies dazu führen, dass die Samples gleichzeitig ungewollt ausgelöst werden.
Testen hoher Raten und/oder langer Testdauern
Der präzise Durchsatz-Timer generiert den Zeitplan und speichert ihn. In den meisten Fällen sollte dies kein Problem darstellen, denken Sie jedoch daran, dass Sie den Zeitplan möglicherweise kürzer als 1.000.000 Abtastungen halten möchten. Es dauert ungefähr 200 ms, um einen Zeitplan für 1.000.000 Abtastungen zu generieren, und der Zeitplan verbraucht 8 Megabyte im Heap. Die Erstellung eines Zeitplans für 10 Millionen Einträge dauert 1-2 Sekunden und verbraucht 80 Megabyte im Heap.
Wenn Sie beispielsweise einen zweiwöchigen Test mit einer Rate von 5.000 pro Stunde durchführen möchten, möchten Sie wahrscheinlich genau 5.000 Proben für jede Stunde haben. Sie können die Eigenschaft Testdauer (Sekunden) des Timers auf 1 Stunde einstellen. Dann würde der Timer einen Zeitplan mit 5.000 Proben für eine Stunde erstellen, und wenn der Zeitplan erschöpft ist, würde der Timer einen Zeitplan für die nächste Stunde generieren.
Gleichzeitig können Sie die Testdauer (Sekunden) auf 2 Wochen einstellen, und der Timer würde einen Zeitplan mit 168.000 Proben = 2 Wochen * 5.000 Proben/Stunde = 2*7*24*500 generieren . Die Generierung des Zeitplans würde ca. 30 ms dauern und etwas mehr als 1 Megabyte verbrauchen.
Burstige Ladung
Es kann Fälle geben, in denen alle Proben paarweise, dreifach usw. kommen sollten. Bestimmte Fälle können über Synchronizing Timer gelöst werden , Precise Throughput Timer hat jedoch eine native Möglichkeit, Anforderungen in Paketen auszugeben. Dieses Verhalten ist standardmäßig deaktiviert und wird mit den Einstellungen für "Sammelabfahrten" gesteuert
- Anzahl der Threads im Stapel (Threads) . Gibt die Anzahl der Proben in einem Stapel an. Beachten Sie, dass die Gesamtzahl der Proben immer noch dem Zieldurchsatz entspricht
- Verzögerung zwischen Threads im Stapel (ms) . Wenn zum Beispiel 42 eingestellt ist und die Stapelgröße 3 ist, dann werden Threads bei x, x+42ms, x+84ms abgehen
Variable Laderate
Obwohl Eigenschaftswerte (z. B. Durchsatz) über Ausdrücke definiert werden können, wird empfohlen, den Wert während des Tests mehr oder weniger gleich zu halten, da es einige Zeit dauert, den neuen Zeitplan neu zu berechnen, um neue Werte anzupassen.
Überwachung
Wenn der nächste Zeitplan generiert wird, protokolliert Precise Throughput Timer eine Nachricht an jmeter.log : 2018-01-04 17:34:03,635 INFO oajtConstantPoissonProcessGenerator: Generated 21 timings (... 20 required, rate 1.0, duration 20, exact lim 20000, i21) in 0 ms. First 15 events will be fired at: 1.1869653574244292 (+1.1869653574244292), 1.4691340403043207 (+0.2821686828798915), 3.638151706179226 (+2.169017665874905), 3.836357090410566 (+0.19820538423134026), 4.709330071408575 (+0.8729729809980085), 5.61330076999953 (+0.903970698590955), ... Dies zeigt, dass die Zeitplanerstellung 0 ms gedauert hat, und es zeigt absolute Zeitstempel in Sekunden. Im obigen Fall wurde die Rate auf 1 pro Sekunde eingestellt, und die tatsächlichen Zeitstempel wurden 1,2 Sekunden, 1,5 Sekunden, 3,6 Sekunden, 3,8 Sekunden, 4,7 Sekunden usw.

Parameter ¶
Timer synchronisieren ¶
Der Zweck des SyncTimer besteht darin, Threads zu blockieren, bis die Anzahl X von Threads blockiert wurde, und dann werden sie alle auf einmal freigegeben. Ein SyncTimer kann somit an verschiedenen Stellen des Testplans große Momentanlasten erzeugen.

Parameter ¶
BeanShell-Timer ¶
Der BeanShell Timer kann verwendet werden, um eine Verzögerung zu erzeugen.
Ausführliche Informationen zur Verwendung von BeanShell finden Sie auf der BeanShell-Website.
Das Testelement unterstützt die Methoden ThreadListener und TestListener . Diese sollten in der Initialisierungsdatei definiert werden. Beispieldefinitionen finden Sie in der Datei BeanShellListeners.bshrc .

Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- bsh.args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Vor dem Aufruf des Skripts werden einige Variablen im BeanShell-Interpreter eingerichtet:
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); - props – (JMeterProperties – Klasse java.util.Properties) – zB props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - gibt Zugriff auf das vorherige SampleResult (falls vorhanden)
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
Wenn die Eigenschaft beanshell.timer.init definiert ist, wird diese zum Laden einer Initialisierungsdatei verwendet, mit der Methoden usw. zur Verwendung im BeanShell-Skript definiert werden können.
JSR223-Timer ¶
Der JSR223-Timer kann verwendet werden, um eine Verzögerung mit einer JSR223-Skriptsprache zu generieren.
Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Vor dem Aufruf des Skripts werden einige Variablen im Skriptinterpreter eingerichtet:
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); - props – (JMeterProperties – Klasse java.util.Properties) – zB props.get("START.HMS"); props.put("PROP1","1234");
- sampler - ( Sampler ) - der aktuelle Sampler
- Label - der Name des Timers
- FileName - der Dateiname (falls vorhanden)
- OUT - System.aus
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
Poisson-Zufallstimer ¶
Dieser Zeitgeber hält jede Thread-Anforderung für eine zufällige Zeitspanne an, wobei die meisten Zeitintervalle in der Nähe eines bestimmten Werts liegen. Die Gesamtverzögerung ist die Summe aus dem Poisson-verteilten Wert und dem Offset-Wert.
Hinweis: Wenn Sie Poisson-Ankünfte modellieren möchten, sollten Sie stattdessen den Precise Throughput Timer verwenden.

Parameter ¶
18.7 Präprozessoren ¶
Präprozessoren werden verwendet, um die Sampler in ihrem Geltungsbereich zu modifizieren.
HTML-Link-Parser ¶
Dieser Modifikator analysiert die HTML-Antwort vom Server und extrahiert Links und Formulare. Ein URL-Testmuster, das diesen Modifikator durchläuft, wird daraufhin untersucht, ob es mit einem der Links oder Formulare „übereinstimmt“, die aus der unmittelbar vorherigen Antwort extrahiert wurden. Es würde dann die Werte im URL-Testbeispiel durch entsprechende Werte aus dem übereinstimmenden Link oder Formular ersetzen. Reguläre Ausdrücke vom Typ Perl werden verwendet, um Übereinstimmungen zu finden.

Betrachten Sie ein einfaches Beispiel: Nehmen wir an, Sie möchten, dass JMeter durch Ihre Site "spidert" und auf einen Link nach dem anderen trifft, der aus dem von Ihrem Server zurückgegebenen HTML geparst wurde (dies ist eigentlich nicht die nützlichste Sache, aber es dient als gutes Beispiel). . Sie würden einen einfachen Controller erstellen und ihm den "HTML Link Parser" hinzufügen. Erstellen Sie dann eine HTTP-Anforderung und setzen Sie die Domäne auf " .* " und den Pfad ebenfalls. Dadurch stimmt Ihr Testmuster mit jedem Link überein, der auf den zurückgegebenen Seiten gefunden wird. Wenn Sie das Spidering auf eine bestimmte Domäne beschränken möchten, ändern Sie den Domänenwert in den gewünschten Wert. Dann werden nur Links zu dieser Domain verfolgt.
Ein nützlicheres Beispiel: Bei einer Web-Umfrageanwendung haben Sie möglicherweise eine Seite mit mehreren Umfrageoptionen als Optionsfelder, die der Benutzer auswählen kann. Nehmen wir an, die Werte der Umfrageoptionen sind sehr dynamisch - möglicherweise benutzergeneriert. Wenn Sie möchten, dass JMeter die Umfrage testet, können Sie entweder Testbeispiele mit fest codierten ausgewählten Werten erstellen oder den HTML-Link-Parser das Formular parsen lassen und eine zufällige Umfrageoption in Ihr URL-Testbeispiel einfügen. Befolgen Sie dazu das obige Beispiel, stellen Sie jedoch beim Konfigurieren der URL-Optionen Ihres Webtest-Controllers sicher, dass Sie " POST " als Methode auswählen. Geben Sie fest codierte Werte für die Domäne , den Pfad und alle zusätzlichen Formularparameter ein. Geben Sie dann für den eigentlichen Parameter des Optionsfelds den Namen ein (sagen wir es 'poll_choice ") und dann " .* " für den Wert dieses Parameters. Wenn der Modifizierer dieses URL-Testmuster untersucht, wird er feststellen, dass es mit dem Umfrageformular "übereinstimmt" (und es sollte daher mit keinem anderen Formular übereinstimmen). Sie haben alle anderen Aspekte des URL-Testbeispiels angegeben), und es ersetzt Ihre Formularparameter durch die übereinstimmenden Parameter aus dem Formular. Da der reguläre Ausdruck " .* " mit allem übereinstimmt, hat der Modifikator wahrscheinlich eine Liste von Optionsfeldern zur Auswahl. Es wird nach dem Zufallsprinzip ausgewählt und ersetzt den Wert in Ihrem URL-Testmuster. Bei jedem Testdurchgang wird ein neuer Zufallswert ausgewählt.

Modifikator zum Umschreiben von HTTP-URLs ¶
Dieser Modifikator funktioniert ähnlich wie der HTML-Link-Parser, außer dass er einen bestimmten Zweck hat, für den er einfacher zu verwenden und effizienter ist als der HTML-Link-Parser. Für Webanwendungen, die URL-Umschreibung verwenden, um Sitzungs-IDs anstelle von Cookies zu speichern, kann dieses Element auf ThreadGroup-Ebene angehängt werden, ähnlich wie der HTTP-Cookie-Manager . Geben Sie ihm einfach den Namen des Sitzungs-ID-Parameters, und er wird ihn auf der Seite finden und das Argument zu jeder Anfrage dieser ThreadGroup hinzufügen.
Alternativ kann dieser Modifikator an ausgewählte Anforderungen angehängt werden und ändert nur diese. Clevere Benutzer werden sogar feststellen, dass dieser Modifikator verwendet werden kann, um Werte zu erfassen, die dem HTML-Link-Parser entgehen .

Parameter ¶
Benutzerparameter ¶
Ermöglicht dem Benutzer, Werte für Benutzervariablen anzugeben, die für einzelne Threads spezifisch sind.
Benutzervariablen können auch im Testplan angegeben werden, jedoch nicht spezifisch für einzelne Threads. In diesem Bereich können Sie eine Reihe von Werten für jede Benutzervariable angeben. Für jeden Thread wird der Variablen nacheinander einer der Werte aus der Reihe zugewiesen. Wenn es mehr Threads als Werte gibt, werden die Werte wiederverwendet. Dies kann beispielsweise verwendet werden, um jedem Thread eine eindeutige Benutzer-ID zuzuweisen. Benutzervariablen können in jedem Feld einer beliebigen JMeter-Komponente referenziert werden.
Die Variable wird angegeben, indem Sie auf die Schaltfläche „ Variable hinzufügen“ unten im Bedienfeld klicken und den Variablennamen in die Spalte „ Name: “ eingeben. Um der Serie einen neuen Wert hinzuzufügen, klicken Sie auf die Schaltfläche „ Benutzer hinzufügen “ und geben Sie den gewünschten Wert in die neu hinzugefügte Spalte ein.
Auf Werte kann in jeder Testkomponente in derselben Threadgruppe zugegriffen werden, indem die Funktionssyntax verwendet wird : ${variable} .
Siehe auch das Element CSV Data Set Config , das sich eher für eine große Anzahl von Parametern eignet

Parameter ¶
BeanShell-Vorprozessor ¶
Der BeanShell PreProcessor ermöglicht es, beliebigen Code anzuwenden, bevor ein Sample genommen wird.
Ausführliche Informationen zur Verwendung von BeanShell finden Sie auf der BeanShell-Website.
Das Testelement unterstützt die Methoden ThreadListener und TestListener . Diese sollten in der Initialisierungsdatei definiert werden. Beispieldefinitionen finden Sie in der Datei BeanShellListeners.bshrc .

Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- bsh.args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Vor dem Aufruf des Skripts werden einige Variablen im BeanShell-Interpreter eingerichtet:
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); - props – (JMeterProperties – Klasse java.util.Properties) – zB props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - gibt Zugriff auf das vorherige SampleResult (falls vorhanden)
- sampler - ( Sampler )- gibt Zugriff auf den aktuellen Sampler
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
Wenn die Eigenschaft beanshell.preprocessor.init definiert ist, wird diese zum Laden einer Initialisierungsdatei verwendet, mit der Methoden usw. zur Verwendung im BeanShell-Skript definiert werden können.
JSR223-Präprozessor ¶
Der JSR223 PreProcessor ermöglicht die Anwendung von JSR223-Skriptcode vor der Entnahme einer Stichprobe.
Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Die folgenden JSR223-Variablen werden für die Verwendung durch das Skript eingerichtet:
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- Label - das String-Label
- FileName - der Name der Skriptdatei (falls vorhanden)
- Parameter - die Parameter (als String)
- args - die Parameter als String-Array (auf Whitespace aufgeteilt)
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); vars.getObject("OBJ2"); - props – (JMeterProperties – Klasse java.util.Properties) – zB props.get("START.HMS"); props.put("PROP1","1234");
- sampler - ( Sampler )- gibt Zugriff auf den aktuellen Sampler
- OUT - System.out - zB OUT.println("Nachricht")
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
JDBC-Präprozessor ¶
Mit dem JDBC PreProcessor können Sie einige SQL-Anweisungen ausführen, kurz bevor ein Beispiel ausgeführt wird. Dies kann nützlich sein, wenn Ihr JDBC-Beispiel einige Daten in der Datenbank benötigt und Sie diese nicht in einer Setup-Thread-Gruppe berechnen können. Einzelheiten finden Sie unter JDBC-Anfrage .
Siehe folgenden Testplan:
Im verknüpften Testplan " Create Price Cut-Off " ruft der JDBC PreProcessor eine gespeicherte Prozedur auf, um einen Price Cut-Off in der Datenbank zu erstellen, diese wird von " Calculate Price Cut-Off " verwendet.

RegEx-Benutzerparameter ¶
Ermöglicht die Angabe dynamischer Werte für HTTP-Parameter, die mithilfe regulärer Ausdrücke aus einer anderen HTTP-Anforderung extrahiert wurden. RegEx-Benutzerparameter sind spezifisch für einzelne Threads.
Mit dieser Komponente können Sie den Referenznamen eines regulären Ausdrucks angeben, der Namen und Werte von HTTP-Anforderungsparametern extrahiert. Gruppennummern regulärer Ausdrücke müssen für den Namen des Parameters und auch für den Wert des Parameters angegeben werden. Die Ersetzung erfolgt nur für Parameter in dem Sampler, der diese RegEx-Benutzerparameter verwendet, deren Name übereinstimmt

Parameter ¶
Angenommen, wir haben eine Anfrage, die ein Formular mit 3 Eingabeparametern zurückgibt, und wir möchten den Wert von 2 davon extrahieren, um sie in die nächste Anfrage einzufügen
- Regulären Ausdruck des Postprozessors für die erste HTTP-Anforderung erstellen
- refName - setzt den Namen eines regulären Ausdrucks Expression ( listParams )
-
Regulärer Ausdruck – Ausdruck, der Attribute für Eingabenamen und Eingabewerte extrahiert Beispiel
: input name="([^"]+?)" value="([^"]+?)" - Vorlage - wäre leer
- match nr - -1 (um alle möglichen Matches zu durchlaufen)
- Erstellen Sie Präprozessor-RegEx-Benutzerparameter für die zweite HTTP-Anforderung
- refName - setzt den gleichen Referenznamen eines regulären Ausdrucks, wäre in unserem Beispiel listParams
- Parameternamen-Gruppennummer - Gruppennummer des regulären Ausdrucks für Parameternamen, wäre in unserem Beispiel 1
- Gruppennummer der Parameterwerte - Gruppennummer des regulären Ausdrucks für Parameterwerte, wäre in unserem Beispiel 2
Siehe auch das Element Regular Expression Extractor , das zum Extrahieren von Parameternamen und -werten verwendet wird
Beispiel-Zeitüberschreitung ¶
Dieser Pre-Processor plant eine Timer-Aufgabe, um eine Probe zu unterbrechen, wenn die Fertigstellung zu lange dauert. Das Timeout wird ignoriert, wenn es null oder negativ ist. Damit dies funktioniert, muss der Sampler Interruptible implementieren. Die folgenden Sampler sind dafür bekannt:
AJP, BeanShell, FTP, HTTP, Soap, AccessLog, MailReader, JMS Subscriber, TCPSampler, TestAction, JavaSampler
Das Testelement ist für den Einsatz vorgesehen, wo individuelle Timeouts wie Connection Timeout oder Response Timeout nicht ausreichen oder der Sampler keine Timeouts unterstützt. Das Timeout sollte ausreichend lang eingestellt werden, damit es bei normalen Tests nicht ausgelöst wird, aber kurz genug, um festgefahrene Samples zu unterbrechen.
[Standardmäßig verwendet JMeter ein Callable, um den Sampler zu unterbrechen. Dies wird im selben Thread wie der Timer ausgeführt. Wenn der Interrupt also lange dauert, kann dies die Verarbeitung nachfolgender Timeouts verzögern. Es wird nicht erwartet, dass dies ein Problem darstellt, aber bei Bedarf kann die Eigenschaft InterruptTimer.useRunnable auf „ true “ gesetzt werden , um einen separaten Runnable-Thread anstelle des Callable zu verwenden.]

Parameter ¶
18.8 Postprozessoren ¶
Wie der Name schon sagt, werden Postprozessoren nach Samplern angewendet. Beachten Sie, dass sie auf alle Sampler im selben Bereich angewendet werden. Um sicherzustellen, dass ein Postprozessor nur auf einen bestimmten Sampler angewendet wird, fügen Sie ihn als untergeordnetes Element des Samplers hinzu.
Postprozessoren werden vor Assertionen ausgeführt, sodass sie keinen Zugriff auf Assertion-Ergebnisse haben und der Stichprobenstatus auch nicht die Ergebnisse von Assertions widerspiegelt. Wenn Sie Zugriff auf Assertionsergebnisse benötigen, versuchen Sie es stattdessen mit einem Listener. Beachten Sie auch, dass die Variable JMeterThread.last_sample_ok auf „ true “ oder „ false “ gesetzt wird, nachdem alle Assertions ausgeführt wurden.
Extraktor für reguläre Ausdrücke ¶
Ermöglicht dem Benutzer das Extrahieren von Werten aus einer Serverantwort mithilfe eines regulären Ausdrucks vom Typ Perl. Als Postprozessor wird dieses Element nach jeder Beispielanforderung in seinem Geltungsbereich ausgeführt, wendet den regulären Ausdruck an, extrahiert die angeforderten Werte, generiert die Vorlagenzeichenfolge und speichert das Ergebnis im angegebenen Variablennamen.

Parameter ¶
- Nur Hauptprobe - gilt nur für die Hauptprobe
- Nur Unterproben - gilt nur für die Unterproben
- Hauptprobe und Unterproben - gilt für beide.
- Zu verwendender JMeter-Variablenname - Die Extraktion soll auf den Inhalt der benannten Variablen angewendet werden
- Body – der Text der Antwort, z. B. der Inhalt einer Webseite (ohne Kopfzeilen)
-
Body (ohne Escapezeichen) – der Text der Antwort, wobei alle Html-Escape-Codes ersetzt wurden. Beachten Sie, dass HTML-Escapezeichen ohne Berücksichtigung des Kontexts verarbeitet werden, sodass einige falsche Ersetzungen vorgenommen werden können.
Beachten Sie, dass sich diese Option stark auf die Leistung auswirkt. Verwenden Sie sie daher nur, wenn es unbedingt erforderlich ist, und seien Sie sich ihrer Auswirkungen bewusst
-
Body as a Document - der extrahierte Text aus verschiedenen Arten von Dokumenten über Apache Tika (siehe Abschnitt View Results Tree Document View).
Beachten Sie, dass die Option Body as a Document die Leistung beeinträchtigen kann, stellen Sie also sicher, dass sie für Ihren Test geeignet ist
- Anforderungsheader – möglicherweise nicht für Nicht-HTTP-Beispiele vorhanden
- Response Header – möglicherweise nicht vorhanden für Nicht-HTTP-Beispiele
- URL
- Antwortcode - z . B. 200
- Antwortnachricht - zB OK
- Verwenden Sie einen Wert von Null, um anzugeben, dass JMeter zufällig eine Übereinstimmung auswählen soll.
- Eine positive Zahl N bedeutet, dass die n -te Übereinstimmung ausgewählt wird.
- Negative Zahlen werden in Verbindung mit dem ForEach-Controller verwendet - siehe unten.
Wenn Sie jedoch mehrere Testelemente haben, die dieselbe Variable setzen, möchten Sie die Variable möglicherweise unverändert lassen, wenn der Ausdruck nicht übereinstimmt. Entfernen Sie in diesem Fall den Standardwert, sobald das Debuggen abgeschlossen ist.
Wenn die Übereinstimmungsnummer auf eine nicht negative Zahl gesetzt ist und eine Übereinstimmung auftritt, werden die Variablen wie folgt festgelegt:
- refName - der Wert der Vorlage
- refName_g n , wobei n = 0 , 1 , 2 - die Gruppen für die Übereinstimmung
- refName_g - die Anzahl der Gruppen in der Regex (außer 0 )
Wenn keine Übereinstimmung auftritt, wird die refName- Variable auf den Standardwert gesetzt (es sei denn, dieser ist nicht vorhanden). Außerdem werden die folgenden Variablen entfernt:
- refName_g0
- refName_g1
- refName_g
Wenn die Übereinstimmungsnummer auf eine negative Zahl eingestellt ist, werden alle möglichen Übereinstimmungen in den Sampler-Daten verarbeitet. Die Variablen werden wie folgt gesetzt:
- refName_matchNr – die Anzahl der gefundenen Übereinstimmungen; könnte 0 sein
- refName_ n , wobei n = 1 , 2 , 3 usw. - die Zeichenfolgen, wie sie von der Vorlage generiert wurden
- refName_ n _g m , wobei m = 0 , 1 , 2 - die Gruppen für Übereinstimmung n
- refName - immer auf den Standardwert gesetzt
- refName_g n - nicht gesetzt
Beachten Sie, dass die Variable refName in diesem Fall immer auf den Standardwert gesetzt ist und die zugehörigen Gruppenvariablen nicht gesetzt sind.
Siehe auch Response Assertion für einige Beispiele zur Angabe von Modifikatoren und für weitere Informationen zu regulären JMeter-Ausdrücken.
CSS-Selektor-Extraktor (früher: CSS/JQuery-Extraktor ) ¶
Ermöglicht dem Benutzer das Extrahieren von Werten aus einer Server-HTML-Antwort mithilfe einer CSS-Selektorsyntax. Als Postprozessor wird dieses Element nach jeder Beispielanforderung in seinem Geltungsbereich ausgeführt, wendet den CSS/JQuery-Ausdruck an, extrahiert die angeforderten Knoten, extrahiert den Knoten als Text oder Attributwert und speichert das Ergebnis im angegebenen Variablennamen.

Parameter ¶
- Nur Hauptprobe - gilt nur für die Hauptprobe
- Nur Unterproben - gilt nur für die Unterproben
- Hauptprobe und Unterproben - gilt für beide.
- Zu verwendender JMeter-Variablenname - Die Extraktion soll auf den Inhalt der benannten Variablen angewendet werden
- E[foo] – ein E - Element mit einem „ foo “-Attribut
- ancestor child - untergeordnete Elemente, die vom Vorfahren abstammen, z. B. .body p findet p Elemente irgendwo unter einem Block mit der Klasse " body "
- :lt(n) - Elemente finden, deren Geschwisterindex (dh ihre Position im DOM-Baum relativ zu ihrem Elternteil) kleiner als n ist ; zB td:lt(3)
- :contains(text) - findet Elemente, die den angegebenen Text enthalten . Bei der Suche wird die Groß-/Kleinschreibung nicht beachtet; zB p:contains(jsoup)
- …
Dies ist die äquivalente Element#attr(name) -Funktion für JSoup, wenn ein Attribut gesetzt ist.
Wenn leer, entspricht dies der Funktion Element#text() für JSoup, wenn für das Attribut kein Wert festgelegt ist.

- Verwenden Sie einen Wert von Null, um anzugeben, dass JMeter zufällig eine Übereinstimmung auswählen soll.
- Eine positive Zahl N bedeutet, dass die n -te Übereinstimmung ausgewählt wird.
- Negative Zahlen werden in Verbindung mit dem ForEach-Controller verwendet - siehe unten.
Wenn Sie jedoch mehrere Testelemente haben, die dieselbe Variable setzen, möchten Sie die Variable möglicherweise unverändert lassen, wenn der Ausdruck nicht übereinstimmt. Entfernen Sie in diesem Fall den Standardwert, sobald das Debuggen abgeschlossen ist.
Wenn die Übereinstimmungsnummer auf eine nicht negative Zahl gesetzt ist und eine Übereinstimmung auftritt, werden die Variablen wie folgt festgelegt:
- refName - der Wert der Vorlage
Wenn keine Übereinstimmung auftritt, wird die refName- Variable auf den Standardwert gesetzt (es sei denn, dieser ist nicht vorhanden).
Wenn die Übereinstimmungsnummer auf eine negative Zahl eingestellt ist, werden alle möglichen Übereinstimmungen in den Sampler-Daten verarbeitet. Die Variablen werden wie folgt gesetzt:
- refName_matchNr – die Anzahl der gefundenen Übereinstimmungen; könnte 0 sein
- refName_n , wobei n = 1 , 2 , 3 usw. - die Zeichenfolgen, wie sie von der Vorlage generiert wurden
- refName - immer auf den Standardwert gesetzt
Beachten Sie, dass die Variable refName in diesem Fall immer auf den Standardwert gesetzt ist.
XPath2-Extraktor ¶

Parameter ¶
- Nur Hauptprobe - gilt nur für die Hauptprobe
- Nur Unterproben - gilt nur für die Unterproben
- Hauptprobe und Unterproben - gilt für beide.
- Zu verwendender JMeter-Variablenname - Die Extraktion soll auf den Inhalt der benannten Variablen angewendet werden
Zum Beispiel würde //title " <title>Apache JMeter</title> " statt " Apache JMeter " zurückgeben.
In diesem Fall würde //title/text() " Apache JMeter " zurückgeben.
- 0 : bedeutet zufällig (Standardwert)
- -1 bedeutet, dass alle Ergebnisse extrahiert werden, sie werden als <Variablenname> _N benannt (wobei N von 1 bis Anzahl der Ergebnisse reicht) .
- X : bedeutet, das X -te Ergebnis zu extrahieren . Wenn dieses X größer als die Anzahl der Übereinstimmungen ist, wird nichts zurückgegeben. Der Standardwert wird verwendet
Um die Verwendung in einem ForEach Controller zu ermöglichen , funktioniert es genauso wie der obige XPath Extractor
XPath2 Extractor bietet einige interessante Werkzeuge wie eine verbesserte Syntax und viel mehr Funktionen als in seiner ersten Version.
Hier sind einige Beispiele:
- abs(/Buch/Seite[2])
- extrahiert den 2. Absolutwert der Seite aus einem Buch
- avg(/Bibliothek/Buch/Seite)
- extrahiert die durchschnittliche Seitenzahl aus allen Büchern in den Bibliotheken
- vergleichen(/buch[1]/seite[2],/buch[2]/seite[2])
- Ganzzahliger Wert gleich 0 zurückgeben, wenn die 2. Seite des ersten Buches gleich der 2. Seite des 2. Buches ist, ansonsten -1 zurückgeben.
Weitere Informationen zu diesen Funktionen finden Sie unter xPath2-Funktionen
XPath-Extraktor ¶

Parameter ¶
- Nur Hauptprobe - gilt nur für die Hauptprobe
- Nur Unterproben - gilt nur für die Unterproben
- Hauptprobe und Unterproben - gilt für beide.
- Zu verwendender JMeter-Variablenname - Die Extraktion soll auf den Inhalt der benannten Variablen angewendet werden
- " Use Tidy " sollte für die HTML-Antwort aktiviert sein. Eine solche Antwort wird mit Tidy in gültiges XHTML (XML-kompatibles HTML) umgewandelt
- " Tidy verwenden " sollte sowohl für XHTML- als auch für XML-Antworten (z. B. RSS) deaktiviert sein.
Zum Beispiel würde //title " <title>Apache JMeter</title> " statt " Apache JMeter " zurückgeben.
In diesem Fall würde //title/text() " Apache JMeter " zurückgeben.
- 0 : bedeutet zufällig
- -1 bedeutet, alle Ergebnisse zu extrahieren (Standardwert), sie werden als <Variablenname> _N benannt (wobei N von 1 bis Anzahl der Ergebnisse geht)
- X : bedeutet, das X -te Ergebnis zu extrahieren . Wenn dieses X größer als die Anzahl der Übereinstimmungen ist, wird nichts zurückgegeben. Der Standardwert wird verwendet
Um die Verwendung in einem ForEach Controller zu ermöglichen , werden die folgenden Variablen bei der Rückgabe gesetzt:
- refName - auf erste (oder einzige) Übereinstimmung gesetzt; wenn keine Übereinstimmung, dann auf Standard setzen
- refName_matchNr - auf Anzahl der Übereinstimmungen gesetzt (kann 0 sein )
- refName_n - n = 1 , 2 , 3 usw. Auf die 1. , 2., 3. Übereinstimmung usw. setzen.
XPath ist eine Abfragesprache, die hauptsächlich auf XSLT-Transformationen ausgerichtet ist. Es ist jedoch auch als generische Abfragesprache für strukturierte Daten nützlich. Weitere Informationen finden Sie unter XPath -Referenz oder XPath-Spezifikation . Hier sind einige Beispiele:
- /html/head/titel
- extrahiert das Titelelement aus der HTML-Antwort
- /buch/seite[2]
- extrahiert 2. Seite aus einem Buch
- /Buchseite
- extrahiert alle Seiten aus einem Buch
- //form[@name='countryForm']//select[@name='country']/option[text()='Tschechische Republik'])/@value
- extrahiert das Wertattribut des Optionselements, das mit dem Text „ Tschechische Republik “ innerhalb des Auswahlelements mit dem Namensattribut „ Land “ innerhalb des Formulars mit dem Namensattribut „ LandForm “ übereinstimmt
- Alle Element- und Attributnamen werden in Kleinbuchstaben umgewandelt
- Tidy versucht, falsch verschachtelte Elemente zu korrigieren. Zum Beispiel - das ursprüngliche (falsche) ul/font/li wird zum korrekten ul/li/font
Als Umgehung für Namespace-Einschränkungen des Xalan XPath-Parsers (Implementierung, auf der JMeter basiert) müssen Sie:
- Stellen Sie eine Eigenschaftendatei bereit (wenn Ihre Datei beispielsweise namespaces.properties heißt ), die Zuordnungen für die Namespace-Präfixe enthält:
prefix1=http\://foo.apache.org prefix2=http\://toto.apache.org …
- Verweisen Sie auf diese Datei in der Datei user.properties mit der Eigenschaft:
xpath.namespace.config=Namespaces.Eigenschaften
//meinnamespace:tagname
//*[lokaler-name()='tagname' und namespace-uri()='uri-for-namespace']uri-für-namespace meinnamespace
JSON JMESPath-Extraktor ¶

Parameter ¶
- Nur Hauptprobe - gilt nur für die Hauptprobe
- Nur Unterproben - gilt nur für die Unterproben
- Hauptprobe und Unterproben - gilt für beide.
- Zu verwendender JMeter-Variablenname - Die Extraktion soll auf den Inhalt der benannten Variablen angewendet werden
- 0 : bedeutet zufällig
- -1 bedeutet, alle Ergebnisse zu extrahieren (Standardwert), sie werden als <Variablenname> _N benannt (wobei N von 1 bis Anzahl der Ergebnisse geht)
- X : bedeutet, das X -te Ergebnis zu extrahieren . Wenn dieses X größer als die Anzahl der Übereinstimmungen ist, wird nichts zurückgegeben. Der Standardwert wird verwendet
JMESPath ist eine Abfragesprache für JSON. Es ist in einer ABNF-Grammatik mit vollständiger Spezifikation beschrieben. Dadurch wird sichergestellt, dass die Sprachsyntax genau definiert ist. Weitere Informationen finden Sie in der JMESPath -Referenz . Hier sind auch einige Beispiele JMESPath Example .
Aktionshandler für Ergebnisstatus ¶

Parameter ¶
- Fortfahren - Ignorieren Sie den Fehler und fahren Sie mit dem Test fort
- Starte nächste Thread-Schleife – führt keine Abtaster aus, die dem fehlerhaften Abtaster für die aktuelle Iteration folgen, und startet die Schleife bei der nächsten Iteration neu
- Thread stoppen – aktueller Thread wird beendet
- Test stoppen – der gesamte Test wird am Ende aller aktuellen Proben gestoppt.
- Test jetzt stoppen – Der gesamte Test wird abrupt beendet. Eventuell laufende Sampler werden nach Möglichkeit unterbrochen.
BeanShell-Postprozessor ¶
Der BeanShell PreProcessor ermöglicht die Anwendung von beliebigem Code nach der Entnahme eines Samples.
BeanShell Post-Processor ignoriert Proben mit Null-Längen-Ergebnisdaten nicht mehr
Ausführliche Informationen zur Verwendung von BeanShell finden Sie auf der BeanShell-Website.
Das Testelement unterstützt die Methoden ThreadListener und TestListener . Diese sollten in der Initialisierungsdatei definiert werden. Beispieldefinitionen finden Sie in der Datei BeanShellListeners.bshrc .

Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- bsh.args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Die folgenden BeanShell-Variablen werden für die Verwendung durch das Skript eingerichtet:
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); - props – (JMeterProperties – Klasse java.util.Properties) – zB props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - gibt Zugriff auf das vorherige SampleResult
- data - (Byte []) - bietet Zugriff auf die aktuellen Beispieldaten
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
Wenn die Eigenschaft beanshell.postprocessor.init definiert ist, wird diese zum Laden einer Initialisierungsdatei verwendet, mit der Methoden usw. zur Verwendung im BeanShell-Skript definiert werden können.
JSR223-Postprozessor ¶
Der JSR223 PostProcessor ermöglicht die Anwendung von JSR223-Skriptcode nach der Entnahme eines Samples.
Parameter ¶
- Parameter - Zeichenfolge, die die Parameter als einzelne Variable enthält
- args - String-Array mit Parametern, aufgeteilt auf Leerzeichen
Vor dem Aufruf des Skripts werden einige Variablen eingerichtet. Beachten Sie, dass dies JSR223-Variablen sind - dh sie können direkt im Skript verwendet werden.
- log - ( Logger ) - kann verwendet werden, um in die Protokolldatei zu schreiben
- Label - das String-Label
- FileName - der Name der Skriptdatei (falls vorhanden)
- Parameter - die Parameter (als String)
- args - die Parameter als String-Array (auf Whitespace aufgeteilt)
- ctx – ( JMeterContext ) – gibt Zugriff auf den Kontext
-
vars - ( JMeterVariables ) - gibt Lese-/Schreibzugriff auf Variablen:
vars.get (Schlüssel); vars.put (Schlüssel, Wert); vars.putObject("OBJ1",neues Objekt()); vars.getObject("OBJ2"); - props – (JMeterProperties – Klasse java.util.Properties) – zB props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - gibt Zugriff auf das vorherige SampleResult (falls vorhanden)
- sampler - ( Sampler )- gibt Zugriff auf den aktuellen Sampler
- OUT - System.out - zB OUT.println("Nachricht")
Einzelheiten zu allen Methoden, die für jede der oben genannten Variablen verfügbar sind, finden Sie im Javadoc
JDBC-Postprozessor ¶
Mit dem JDBC PostProcessor können Sie einige SQL-Anweisungen direkt nach der Ausführung eines Beispiels ausführen. Dies kann nützlich sein, wenn Ihr JDBC-Beispiel einige Daten ändert und Sie den Status auf den Stand vor der Ausführung des JDBC-Beispiels zurücksetzen möchten.
Im verknüpften Testplan "JDBC PostProcessor" ruft der JDBC PostProcessor eine gespeicherte Prozedur auf, um den vom PreProcessor erstellten Price Cut-Off aus der Datenbank zu löschen.

JSON-Extraktor ¶
Mit dem JSON PostProcessor können Sie Daten aus JSON-Antworten mithilfe der JSON-PATH-Syntax extrahieren. Dieser Postprozessor ist dem Extraktor für reguläre Ausdrücke sehr ähnlich. Es muss als untergeordnetes Element von HTTP Sampler oder einem anderen Sampler mit Antworten platziert werden. Damit können Sie auf sehr einfache Weise Textinhalte extrahieren, siehe JSON-Pfadsyntax .
Parameter ¶
- 0 : bedeutet zufällig (Standardwert)
- -1 bedeutet, dass alle Ergebnisse extrahiert werden, sie werden als <Variablenname> _N benannt (wobei N von 1 bis Anzahl der Ergebnisse reicht) .
- X : bedeutet, das X -te Ergebnis zu extrahieren . Wenn dieses X größer als die Anzahl der Übereinstimmungen ist, wird nichts zurückgegeben. Der Standardwert wird verwendet

Grenzextraktor ¶
Ermöglicht dem Benutzer das Extrahieren von Werten aus einer Serverantwort unter Verwendung linker und rechter Grenzen. Als Postprozessor wird dieses Element nach jeder Beispielanforderung in seinem Geltungsbereich ausgeführt, testet die Grenzen, extrahiert die angeforderten Werte, generiert die Vorlagenzeichenfolge und speichert das Ergebnis im angegebenen Variablennamen.

Parameter ¶
- Nur Hauptprobe - gilt nur für die Hauptprobe
- Nur Unterproben - gilt nur für die Unterproben
- Hauptprobe und Unterproben - gilt für beide.
- Zu verwendender JMeter-Variablenname – Die Assertion muss auf den Inhalt der benannten Variablen angewendet werden
- Body – der Text der Antwort, z. B. der Inhalt einer Webseite (ohne Kopfzeilen)
-
Body (ohne Escapezeichen) – der Text der Antwort, wobei alle Html-Escape-Codes ersetzt wurden. Beachten Sie, dass HTML-Escapezeichen ohne Berücksichtigung des Kontexts verarbeitet werden, sodass einige falsche Ersetzungen vorgenommen werden können.
Beachten Sie, dass sich diese Option stark auf die Leistung auswirkt. Verwenden Sie sie daher nur, wenn es unbedingt erforderlich ist, und seien Sie sich ihrer Auswirkungen bewusst
-
Body as a Document - der extrahierte Text aus verschiedenen Arten von Dokumenten über Apache Tika (siehe Abschnitt View Results Tree Document View).
Beachten Sie, dass die Option Body as a Document die Leistung beeinträchtigen kann, stellen Sie also sicher, dass sie für Ihren Test geeignet ist
- Anforderungsheader – möglicherweise nicht für Nicht-HTTP-Beispiele vorhanden
- Response Header – möglicherweise nicht vorhanden für Nicht-HTTP-Beispiele
- URL
- Antwortcode - z . B. 200
- Antwortnachricht - zB OK
- Verwenden Sie einen Wert von Null, um anzugeben, dass JMeter zufällig eine Übereinstimmung auswählen soll.
- Eine positive Zahl N bedeutet, dass die n -te Übereinstimmung ausgewählt wird.
- Negative Zahlen werden in Verbindung mit dem ForEach-Controller verwendet - siehe unten.
Wenn Sie jedoch mehrere Testelemente haben, die dieselbe Variable setzen, möchten Sie die Variable möglicherweise unverändert lassen, wenn der Ausdruck nicht übereinstimmt. Entfernen Sie in diesem Fall den Standardwert, sobald das Debuggen abgeschlossen ist.
Wenn die Übereinstimmungsnummer auf eine nicht negative Zahl gesetzt ist und eine Übereinstimmung auftritt, werden die Variablen wie folgt festgelegt:
- refName – der Wert der Extraktion
Wenn keine Übereinstimmung auftritt, wird die refName- Variable auf den Standardwert gesetzt (es sei denn, dieser ist nicht vorhanden).
Wenn die Übereinstimmungsnummer auf eine negative Zahl eingestellt ist, werden alle möglichen Übereinstimmungen in den Sampler-Daten verarbeitet. Die Variablen werden wie folgt gesetzt:
- refName_matchNr – die Anzahl der gefundenen Übereinstimmungen; könnte 0 sein
- refName_ n , wobei n = 1 , 2 , 3 usw. - die Zeichenfolgen, wie sie von der Vorlage generiert wurden
- refName_ n _g m , wobei m = 0 , 1 , 2 - die Gruppen für Übereinstimmung n
- refName - immer auf den Standardwert gesetzt
Beachten Sie, dass die Variable refName in diesem Fall immer auf den Standardwert gesetzt ist und die zugehörigen Gruppenvariablen nicht gesetzt sind.
18.9 Verschiedene Funktionen ¶
Testplan ¶
Im Testplan werden die allgemeinen Einstellungen für einen Test festgelegt.
Statische Variablen können für Werte definiert werden, die während eines Tests wiederholt werden, z. B. Servernamen. Beispielsweise könnte die Variable SERVER als www.example.com definiert werden und der Rest des Testplans könnte darauf als ${SERVER} verweisen . Dies vereinfacht spätere Namensänderungen.
Wenn derselbe Variablenname für eines oder mehrere Elemente der benutzerdefinierten Variablenkonfiguration wiederverwendet wird , wird der Wert auf die letzte Definition im Testplan gesetzt (von oben nach unten gelesen). Solche Variablen sollten für Elemente verwendet werden, die sich zwischen Testläufen ändern können, aber während eines Testlaufs gleich bleiben.
Die Auswahl von Functional Testing weist JMeter an, die zusätzlichen Probeninformationen – Response Data und Sampler Data – in allen Ergebnisdateien zu speichern. Dies erhöht die zum Ausführen eines Tests erforderlichen Ressourcen und kann die Leistung von JMeter beeinträchtigen. Wenn nur für einen bestimmten Sampler mehr Daten erforderlich sind, fügen Sie ihm einen Listener hinzu und konfigurieren Sie die Felder nach Bedarf.
Außerdem gibt es hier eine Option, um JMeter anzuweisen, die Thread-Gruppe seriell statt parallel auszuführen.
TearDown-Thread-Gruppen nach dem Herunterfahren der Haupt-Threads ausführen: Wenn diese Option ausgewählt ist, werden die TearDown-Gruppen (falls vorhanden) nach dem ordnungsgemäßen Herunterfahren der Haupt-Threads ausgeführt. Die TearDown-Threads werden nicht ausgeführt, wenn der Test zwangsweise beendet wird.
Testplan bietet jetzt eine einfache Möglichkeit, Klassenpfadeinstellungen zu einem bestimmten Testplan hinzuzufügen. Die Funktion ist additiv, was bedeutet, dass Sie JAR-Dateien oder Verzeichnisse hinzufügen können, aber das Entfernen eines Eintrags erfordert einen Neustart von JMeter.
JMeter-Eigenschaften bieten auch einen Eintrag zum Laden zusätzlicher Klassenpfade. Bearbeiten Sie in jmeter.properties „ user.classpath “ oder „ plugin_dependency_paths “, um zusätzliche Bibliotheken einzuschließen. Weitere Informationen finden Sie unter Klassenpfad von JMeter und Konfigurieren von JMeter.

Themengruppe ¶
Eine Thread-Gruppe definiert einen Pool von Benutzern, die einen bestimmten Testfall auf Ihrem Server ausführen. In der Thread-Gruppen-GUI können Sie die Anzahl der simulierten Benutzer (Anzahl der Threads), die Hochlaufzeit (wie lange es dauert, alle Threads zu starten), die Anzahl der Testdurchführungen und optional einen Start steuern und stoppen Sie die Zeit für den Test.
Siehe auch TearDown-Thread-Gruppe und SetUp-Thread-Gruppe .
Bei Verwendung des Schedulers führt JMeter die Thread-Gruppe aus, bis entweder die Anzahl der Schleifen oder die Dauer/Endzeit erreicht ist – je nachdem, was zuerst eintritt. Beachten Sie, dass die Bedingung nur zwischen Proben überprüft wird; Wenn die Endbedingung erreicht ist, wird dieser Thread beendet. JMeter unterbricht keine Sampler, die auf eine Antwort warten, daher kann die Endzeit beliebig verzögert werden.

Seit JMeter 3.0 können Sie eine Auswahl von Thread-Gruppen ausführen, indem Sie sie auswählen und mit der rechten Maustaste klicken. Ein Popup-Menü wird angezeigt:

Beachten Sie, dass Sie drei Optionen haben, um die Auswahl von Thread-Gruppen auszuführen:
- Anfang
- Starten Sie nur die ausgewählten Thread-Gruppen
- Starten Sie ohne Pausen
- Starten Sie nur die ausgewählten Thread-Gruppen, aber ohne die Timer auszuführen
- Bestätigen
- Starten Sie die ausgewählten Thread-Gruppen nur im Validierungsmodus. Standardmäßig führt dies die Thread-Gruppe im Validierungsmodus aus (siehe unten).
Dieser Modus ermöglicht die schnelle Validierung einer Thread-Gruppe, indem er mit einem Thread, einer Iteration, ohne Timer und ohne auf 0 gesetzte Startverzögerung ausgeführt wird . Das Verhalten kann mit einigen Eigenschaften durch Einstellung in user.properties geändert werden :
- testplan_validation.nb_threads_per_thread_group
- Anzahl der Threads, die zum Validieren einer Thread-Gruppe verwendet werden sollen, standardmäßig 1
- testplan_validation.ignore_timers
- Timer ignorieren, wenn die Thread-Gruppe des Plans validiert wird, standardmäßig 1
- testplan_validation.number_iterations
- Anzahl der zur Validierung einer Thread-Gruppe zu verwendenden Iterationen
- testplan_validation.tpc_force_100_pct
- Ob der Durchsatzcontroller im Prozentmodus so ausgeführt werden soll, als ob der Prozentsatz 100 % wäre. Standardmäßig falsch
Parameter ¶
- Fortfahren - Ignorieren Sie den Fehler und fahren Sie mit dem Test fort
- Nächste Thread-Schleife starten – Ignorieren Sie den Fehler, starten Sie die nächste Schleife und fahren Sie mit dem Test fort
- Thread stoppen – aktueller Thread wird beendet
- Test stoppen – der gesamte Test wird am Ende aller aktuellen Proben gestoppt.
- Test jetzt stoppen – Der gesamte Test wird abrupt beendet. Eventuell laufende Sampler werden nach Möglichkeit unterbrochen.
Wenn diese Option nicht ausgewählt ist, werden alle Threads erstellt, wenn der Test beginnt (sie pausieren dann für den entsprechenden Anteil der Hochlaufzeit). Dies ist die ursprüngliche Standardeinstellung und eignet sich für Tests, bei denen Threads während des größten Teils des Tests aktiv sind.
SSL-Manager ¶
Der SSL-Manager ist eine Möglichkeit, ein Client-Zertifikat auszuwählen, damit Sie Anwendungen testen können, die Public Key Infrastructure (PKI) verwenden. Es wird nur benötigt, wenn Sie die entsprechenden Systemeigenschaften nicht eingerichtet haben.
Sie können entweder einen Schlüsselspeicher im Java Key Store (JKS)-Format oder eine Public Key Certificate Standard #12 (PKCS12)-Datei für Ihre Client-Zertifikate verwenden. Es gibt eine Funktion der JSSE-Bibliotheken, die erfordert, dass Sie ein mindestens sechsstelliges Passwort auf Ihrem Schlüssel haben (zumindest für das Keytool-Dienstprogramm, das mit Ihrem JDK geliefert wird).
Um das Client-Zertifikat auszuwählen, wählen Sie in der Menüleiste Ihnen wird ein Dateifinder angezeigt, der standardmäßig nach PKCS12-Dateien sucht. Ihre PKCS12-Datei muss die Erweiterung „ .p12 “ haben, damit SSL Manager sie als PKCS12-Datei erkennt. Jede andere Datei wird wie ein durchschnittlicher JKS-Schlüsselspeicher behandelt. Wenn JSSE korrekt installiert ist, werden Sie zur Eingabe des Kennworts aufgefordert. Das Textfeld verdeckt die Zeichen, die Sie an dieser Stelle eingeben, nicht – stellen Sie also sicher, dass Ihnen niemand über die Schulter schaut. Die aktuelle Implementierung geht davon aus, dass das Passwort für den Schlüsselspeicher auch das Passwort für den privaten Schlüssel des Clients ist, als der Sie sich authentifizieren möchten.
Oder Sie können die entsprechenden Systemeigenschaften festlegen – siehe die Datei system.properties .
Wenn Sie Ihren Test das nächste Mal ausführen, untersucht der SSL-Manager Ihren Schlüsselspeicher, um festzustellen, ob ihm mindestens ein Schlüssel zur Verfügung steht. Wenn es nur einen Schlüssel gibt, wählt SSL Manager ihn für Sie aus. Wenn es mehr als einen Schlüssel gibt, wählt er gegenwärtig den ersten Schlüssel aus. Es gibt derzeit keine Möglichkeit, andere Einträge im Schlüsselspeicher auszuwählen, daher muss der gewünschte Schlüssel der erste sein.
Dinge, auf die Sie achten solltenSie müssen Ihr Zertifizierungsstellenzertifikat (CA) ordnungsgemäß installiert haben, wenn es nicht von einem der fünf CA-Zertifikate signiert ist, die mit Ihrem JDK geliefert werden. Eine Methode zur Installation besteht darin, Ihr CA-Zertifikat in eine JKS-Datei zu importieren und die JKS-Datei " jssecacerts " zu nennen. Legen Sie die Datei im lib/security - Ordner Ihrer JRE ab . Diese Datei wird vor der Datei " cacerts " im selben Verzeichnis gelesen. Beachten Sie, dass die in „ cacerts “ installierten Zertifikate nicht verwendet werden , solange die Datei „ jssecacerts “ existiert. Dies kann zu Problemen für Sie führen. Wenn es Ihnen nichts ausmacht, Ihr CA-Zertifikat in die Datei " cacerts"-Datei, dann können Sie sich mit allen installierten CA-Zertifikaten authentifizieren.
HTTP(S) Test Script Recorder (früher: HTTP Proxy Server ) ¶
Der HTTP(S) Test Script Recorder ermöglicht es JMeter, Ihre Aktionen abzufangen und aufzuzeichnen, während Sie Ihre Webanwendung mit Ihrem normalen Browser durchsuchen. JMeter erstellt Testmusterobjekte und speichert sie direkt in Ihrem Testplan, während Sie fortfahren (so dass Sie Muster interaktiv anzeigen können, während Sie sie erstellen). Stellen Sie sicher, dass Sie diese Wiki-Seite
lesen , um JMeter korrekt einzurichten.
Um den Recorder zu verwenden, fügen Sie das Element HTTP(S) Test Script Recorder hinzu. Klicken Sie mit der rechten Maustaste auf das Testplanelement, um das Menü „Hinzufügen“ aufzurufen: ( ).
Der Rekorder ist als HTTP(S)-Proxy-Server implementiert. Sie müssen Ihren Browser so einrichten, dass er den Proxy für alle HTTP- und HTTPS-Anforderungen verwendet.
Verwenden Sie idealerweise den privaten Browsermodus, wenn Sie die Sitzung aufzeichnen. Dies soll sicherstellen, dass der Browser ohne gespeicherte Cookies startet und verhindert, dass bestimmte Änderungen gespeichert werden. Beispielsweise lässt Firefox nicht zu, dass Zertifikatsüberschreibungen dauerhaft gespeichert werden.
HTTPS-Aufzeichnung und Zertifikate
HTTPS-Verbindungen verwenden Zertifikate, um die Verbindung zwischen dem Browser und dem Webserver zu authentifizieren. Bei einer Verbindung über HTTPS präsentiert der Server dem Browser das Zertifikat. Um das Zertifikat zu authentifizieren, überprüft der Browser, ob das Serverzertifikat von einer Zertifizierungsstelle (CA) signiert ist, die mit einer ihrer integrierten Stammzertifizierungsstellen verknüpft ist.
JMeter muss ein eigenes Zertifikat verwenden, damit es die HTTPS-Verbindung vom Browser abfangen kann. Tatsächlich muss JMeter vorgeben, der Zielserver zu sein.
JMeter generiert seine eigenen Zertifikate. Diese werden mit einer durch die Eigenschaft proxy.cert.validity definierten Gültigkeitsdauer , standardmäßig 7 Tagen und zufälligen Passwörtern generiert. Wenn JMeter erkennt, dass es unter Java 8 oder höher ausgeführt wird, generiert es nach Bedarf Zertifikate für jeden Zielserver (dynamischer Modus), es sei denn, die folgende Eigenschaft ist definiert: proxy.cert.dynamic_keys=false. Bei Verwendung des dynamischen Modus gilt das Zertifikat für den richtigen Hostnamen und wird von einem JMeter-generierten CA-Zertifikat signiert. Standardmäßig wird dieses CA-Zertifikat vom Browser nicht als vertrauenswürdig eingestuft, es kann jedoch als vertrauenswürdiges Zertifikat installiert werden. Sobald dies geschehen ist, werden die generierten Serverzertifikate vom Browser akzeptiert. Das hat den Vorteil, dass auch eingebettete HTTPS-Ressourcen abgefangen werden können und die Browser-Checks nicht für jeden neuen Server überschrieben werden müssen.
Sofern kein Keystore bereitgestellt wird (und Sie die Eigenschaft proxy.cert.alias definieren ), muss JMeter die Keytool-Anwendung verwenden, um die Keystore-Einträge zu erstellen. JMeter enthält Code, um zu überprüfen, ob keytool verfügbar ist, indem an verschiedenen Standardorten gesucht wird. Wenn JMeter die Keytool-Anwendung nicht finden kann, wird ein Fehler gemeldet. Bei Bedarf kann die Systemeigenschaft keytool.directory verwendet werden, um JMeter mitzuteilen, wo Keytool zu finden ist. Dies sollte in der Datei system.properties definiert werden .
Die JMeter-Zertifikate werden (falls erforderlich) generiert, wenn die Schaltfläche Start gedrückt wird.
Bei Bedarf können Sie JMeter dazu zwingen, den Keystore (und die exportierten Zertifikate – ApacheJMeterTemporaryRootCA[.usr|.crt] ) neu zu generieren, indem Sie die Keystore-Datei proxyserver.jks aus dem JMeter-Verzeichnis löschen.
Dieses Zertifikat gehört nicht zu den Zertifikaten, denen Browser normalerweise vertrauen, und ist nicht für den richtigen Host bestimmt.
Als Konsequenz:
- Der Browser sollte einen Dialog anzeigen, in dem Sie gefragt werden, ob Sie das Zertifikat akzeptieren möchten oder nicht. Zum Beispiel:
1) Der Name des Servers „ www.example.com “ stimmt nicht mit dem Namen des Zertifikats überein " _ JMeter Root CA für Aufzeichnung (NUR INSTALLIEREN, WENN ES IHNEN IST) ". Vielleicht versucht jemand, Sie zu belauschen. 2) Das Zertifikat für „ _ JMeter Root CA for recording (INSTALL ONLY IF IT S YOURS) “ ist von der unbekannten Zertifizierungsstelle signiert " _ JMeter Root CA für Aufzeichnung (NUR INSTALLIEREN, WENN ES IHNEN IST) ". Es kann nicht überprüft werden, ob es sich um ein gültiges Zertifikat handelt.
Sie müssen das Zertifikat akzeptieren, damit der JMeter-Proxy den SSL-Datenverkehr abfangen kann, um ihn aufzuzeichnen. Akzeptieren Sie dieses Zertifikat jedoch nicht dauerhaft; es sollte nur vorübergehend akzeptiert werden. Browser fordern diesen Dialog nur für das Zertifikat der Haupt-URL an, nicht für die auf der Seite geladenen Ressourcen wie Bilder, CSS- oder JavaScript-Dateien, die auf einem gesicherten externen CDN gehostet werden. Wenn Sie über solche Ressourcen verfügen (z. B. Google Mail), müssen Sie zuerst manuell zu diesen anderen Domänen navigieren, um das Zertifikat von JMeter für sie zu akzeptieren. Suchen Sie in jmeter.log nach sicheren Domänen, für die Sie ein Zertifikat registrieren müssen. - Wenn der Browser bereits ein validiertes Zertifikat für diese Domain registriert hat, erkennt der Browser JMeter als Sicherheitsverletzung und weigert sich, die Seite zu laden. In diesem Fall müssen Sie das vertrauenswürdige Zertifikat aus dem Schlüsselspeicher Ihres Browsers entfernen.
Versionen von JMeter ab 2.10 unterstützen diese Methode weiterhin und werden dies auch weiterhin tun, wenn Sie die folgende Eigenschaft definieren: proxy.cert.alias Die folgenden Eigenschaften können verwendet werden, um das verwendete Zertifikat zu ändern:
- proxy.cert.directory – das Verzeichnis, in dem das Zertifikat zu finden ist (Standard = JMeter bin/ )
- proxy.cert.file – Name der Keystore-Datei (Standard „ proxyserver.jks “)
- proxy.cert.keystorepass - Keystore-Passwort (Standard " password ") [Ignoriert bei Verwendung des JMeter-Zertifikats]
- proxy.cert.keypassword - Zertifikatsschlüssel-Passwort (Standard " password ") [Ignoriert bei Verwendung des JMeter-Zertifikats]
- proxy.cert.type – der Zertifikatstyp (Standard „ JKS “) [Ignoriert bei Verwendung des JMeter-Zertifikats]
- proxy.cert.factory – die Fabrik (Standard „ SunX509 “) [Ignoriert bei Verwendung des JMeter-Zertifikats]
- proxy.cert.alias – der Alias für den zu verwendenden Schlüssel. Wenn dies definiert ist, versucht JMeter nicht, seine eigenen Zertifikate zu generieren.
- proxy.ssl.protocol - das zu verwendende Protokoll (Standard " SSLv3 ")
Installieren des JMeter-CA-Zertifikats für die HTTPS-Aufzeichnung
Wie oben erwähnt, kann JMeter, wenn es unter Java 8 ausgeführt wird, Zertifikate für jeden Server generieren. Damit dies reibungslos funktioniert, muss das von JMeter verwendete Root-CA-Signaturzertifikat vom Browser als vertrauenswürdig eingestuft werden. Beim ersten Start des Recorders generiert dieser ggf. die Zertifikate. Das Root-CA-Zertifikat wird in eine Datei mit dem Namen ApacheJMeterTemporaryRootCA im aktuellen Startverzeichnis exportiert. Wenn die Zertifikate eingerichtet wurden, zeigt JMeter einen Dialog mit den aktuellen Zertifikatsdetails. An dieser Stelle kann das Zertifikat gemäß den nachstehenden Anweisungen in den Browser importiert werden.
Beachten Sie, dass der Browser nach der Installation des Root-CA-Zertifikats als vertrauenswürdige CA allen von ihm signierten Zertifikaten vertraut. Bis das Zertifikat abläuft oder das Zertifikat aus dem Browser entfernt wird, wird der Benutzer nicht gewarnt, dass auf das Zertifikat vertraut wird. Jeder, der an den Keystore und das Passwort kommt, kann das Zertifikat verwenden, um Zertifikate zu generieren, die von allen Browsern akzeptiert werden, die dem JMeter-Root-CA-Zertifikat vertrauen. Aus diesem Grund werden das Passwort für den Schlüsselspeicher und private Schlüssel zufällig generiert und eine kurze Gültigkeitsdauer verwendet. Die Passwörter werden im lokalen Einstellungsbereich gespeichert. Bitte stellen Sie sicher, dass nur vertrauenswürdige Benutzer Zugriff auf den Host mit dem Schlüsselspeicher haben.

Installation des Zertifikats in Firefox
Wählen Sie die folgenden Optionen:
- Werkzeug-Optionen
- Erweitert / Zertifikate
- Zertifikate anzeigen
- Behörden
- Importieren …
- Navigieren Sie zum Startverzeichnis von JMeter, klicken Sie auf die Datei ApacheJMeterTemporaryRootCA.crt und drücken Sie auf Öffnen
- Klicken Sie auf Anzeigen und überprüfen Sie, ob die Zertifikatsdetails mit denen übereinstimmen, die vom JMeter Test Script Recorder angezeigt werden
- Wenn OK, wählen Sie „ Dieser Zertifizierungsstelle vertrauen, um Websites zu identifizieren “ und drücken Sie OK
- Schließen Sie Dialoge ggf. durch Drücken von OK
Installation des Zertifikats in Chrome oder Internet Explorer
Sowohl Chrome als auch Internet Explorer verwenden denselben Truststore für Zertifikate.
- Navigieren Sie zum JMeter-Startverzeichnis, klicken Sie auf die Datei ApacheJMeterTemporaryRootCA.crt und öffnen Sie sie
- Klicken Sie auf die Registerkarte „ Details “ und überprüfen Sie, ob die Zertifikatsdetails mit denen übereinstimmen, die vom JMeter Test Script Recorder angezeigt werden
- Wenn OK, gehen Sie zurück zur Registerkarte „ Allgemein “ und klicken Sie auf „ Zertifikat installieren … “ und folgen Sie den Anweisungen des Assistenten
Installation des Zertifikats in Opera
- Extras / Einstellungen / Erweitert / Sicherheit
- Zertifikate verwalten …
- Wählen Sie die Registerkarte " Zwischenprodukt " und klicken Sie auf " Importieren … " .
- Navigieren Sie zum JMeter-Startverzeichnis, klicken Sie auf die Datei ApacheJMeterTemporaryRootCA.usr und öffnen Sie sie

Parameter ¶
Beispiel: *.example.com,*.subdomain.example.com
Beachten Sie, dass Wildcard-Domains nur auf einer Ebene gelten, dh abc.subdomain.example.com stimmt mit *.subdomain.example.com überein , aber nicht mit *.example.com
- Sampler nicht gruppieren – speichert alle aufgenommenen Sampler sequentiell, ohne Gruppierung.
- Fügen Sie Trennzeichen zwischen Gruppen hinzu - fügen Sie einen Controller mit dem Namen " -------------- " hinzu, um eine visuelle Trennung zwischen den Gruppen zu erstellen. Andernfalls werden die Sampler alle sequentiell gespeichert.
- Fügen Sie jede Gruppe in einen neuen Controller ein - erstellen Sie einen neuen einfachen Controller für jede Gruppe und speichern Sie alle Sampler für diese Gruppe darin.
- Nur 1. Probenehmer jeder Gruppe speichern - nur die erste Anfrage in jeder Gruppe wird aufgezeichnet. Die Flags „ Redirects folgen “ und „ Alle eingebetteten Ressourcen abrufen … “ werden in diesen Samplern aktiviert.
- Fügen Sie jede Gruppe in einen neuen Transaktionscontroller ein - erstellen Sie einen neuen Transaktionscontroller für jede Gruppe und speichern Sie alle Sampler für diese Gruppe darin.
Aufzeichnung und Weiterleitungen
Während der Aufzeichnung folgt der Browser einer Umleitungsantwort und generiert eine zusätzliche Anfrage. Der Proxy zeichnet sowohl die ursprüngliche Anfrage als auch die umgeleitete Anfrage auf (vorbehaltlich der konfigurierten Ausschlüsse). Bei den generierten Beispielen ist standardmäßig „ Weiterleitungen folgen “ ausgewählt, da dies im Allgemeinen besser ist.
Wenn JMeter nun so eingestellt ist, dass es der Umleitung während der Wiedergabe folgt, wird es die ursprüngliche Anfrage ausgeben und dann die aufgezeichnete Umleitungsanfrage wiedergeben. Um diese doppelte Wiedergabe zu vermeiden, versucht JMeter zu erkennen, wenn ein Sample das Ergebnis einer vorherigen Umleitung ist. Wenn die aktuelle Antwort eine Umleitung ist, speichert JMeter die Umleitungs-URL. Wenn die nächste Anfrage empfangen wird, wird sie mit der gespeicherten Weiterleitungs-URL verglichen, und wenn es eine Übereinstimmung gibt, deaktiviert JMeter das generierte Beispiel. Es fügt auch Kommentare zur Weiterleitungskette hinzu. Dies setzt voraus, dass alle Anforderungen in einer Umleitungskette ohne dazwischenliegende Anforderungen aufeinander folgen. Um die Umleitungserkennung zu deaktivieren, setzen Sie die Eigenschaft proxy.redirect.disabling=false
Enthält und schließt aus
Die Include- und Exclude-Muster werden als reguläre Ausdrücke behandelt (unter Verwendung von Jakarta ORO). Sie werden mit dem Hostnamen, dem Port (tatsächlich oder impliziert), dem Pfad und der Abfrage (falls vorhanden) jeder Browseranforderung abgeglichen. Wenn die URL, die Sie durchsuchen,
„ http://localhost/jmeter/index.html?username=xxxx “ lautet,
wird der reguläre Ausdruck anhand der Zeichenfolge
„ localhost:80/jmeter/index.html?username=xxxx “ getestet ".
Wenn Sie also alle .html- Dateien einschließen möchten, könnte Ihr regulärer Ausdruck so aussehen:
" .*\.html(\?.*)? " - oder " .*\.html
, wenn Sie wissen, dass es keine Abfragezeichenfolge gibt oder Sie möchten nur HTML-Seiten ohne Abfragezeichenfolgen.
Wenn Include-Muster vorhanden sind, muss die URL mit mindestens einem der Muster übereinstimmen, andernfalls wird sie nicht aufgezeichnet. Wenn Ausschlussmuster vorhanden sind, darf die URL mit keinem der Muster übereinstimmen , da sie sonst nicht aufgezeichnet wird. Mit einer Kombination aus Einschließen und Ausschließen sollten Sie in der Lage sein, aufzuzeichnen, woran Sie interessiert sind, und überspringen, was Sie nicht interessiert.
Daher wird " \.html " nicht mit localhost:80/index.html übereinstimmen
Erfassen binärer POST-Daten
JMeter kann binäre POST-Daten erfassen. Um zu konfigurieren, welche Inhaltstypen als binär behandelt werden, aktualisieren Sie die JMeter-Eigenschaft proxy.binary.types . Die Standardeinstellungen sind wie folgt:
# Diese Inhaltstypen werden behandelt, indem die Anfrage in einer Datei gespeichert wird: proxy.binary.types=application/x-amf,application/x-java-serialized-object # Die Dateien werden in diesem Verzeichnis gespeichert: proxy.binary.directory=user.dir # Die Dateien werden mit diesem Datei-Dateiendung erstellt: proxy.binary.filesuffix=.binary
Timer hinzufügen
Es ist auch möglich, dass der Proxy dem aufgezeichneten Skript Timer hinzufügt. Erstellen Sie dazu direkt in der Komponente HTTP(S) Test Script Recorder einen Timer. Der Proxy fügt eine Kopie dieses Timers in jedes Sample ein, das er aufzeichnet, oder in das erste Sample jeder Gruppe, wenn Sie die Gruppierung verwenden. Diese Kopie wird dann in ihren Eigenschaften nach Vorkommen der Variablen ${T} durchsucht , und alle derartigen Vorkommen werden durch die Zeitlücke vom vorherigen aufgezeichneten Sampler (in Millisekunden) ersetzt.
Wenn Sie bereit sind zu beginnen, klicken Sie auf „ Start “.
Wo werden Samples aufgenommen?
JMeter platziert die aufgezeichneten Samples in dem von Ihnen gewählten Target Controller. Wenn Sie die Standardoption „ Aufzeichnungscontroller verwenden “ wählen, werden sie im ersten Aufzeichnungscontroller gespeichert, der im Testobjektbaum gefunden wird (stellen Sie also sicher, dass Sie einen Aufzeichnungscontroller hinzufügen, bevor Sie mit der Aufzeichnung beginnen).
Wenn der Proxy keine Samples aufzuzeichnen scheint, kann dies daran liegen, dass der Browser den Proxy nicht wirklich verwendet. Um zu überprüfen, ob dies der Fall ist, versuchen Sie, den Proxy zu stoppen. Wenn der Browser immer noch Seiten herunterlädt, hat er keine Anfragen über den Proxy gesendet. Überprüfen Sie die Browseroptionen. Wenn Sie versuchen, von einem Server aufzuzeichnen, der auf demselben Host ausgeführt wird, überprüfen Sie, ob der Browser nicht auf „ Proxyserver für lokale Adressen umgehen“ eingestellt ist (dieses Beispiel stammt von IE7, aber es gibt ähnliche Optionen für andere Browser). Wenn JMeter keine Browser-URLs wie http://localhost/ oder http://127.0.0.1/ aufzeichnet , versuchen Sie, den Non-Loopback-Hostnamen oder die IP-Adresse zu verwenden, z. B. http://myhost/ oder http://192.168. 0,2/ .
Handhabung von HTTP-Request-Standardwerten
Wenn der HTTP(S) Test Script Recorder aktivierte HTTP-Anforderungsstandards direkt in dem Controller findet, in dem Beispiele gespeichert werden, oder direkt in einem seiner übergeordneten Controller, weisen die aufgezeichneten Beispiele leere Felder für die von Ihnen angegebenen Standardwerte auf. Sie können dieses Verhalten weiter steuern, indem Sie ein HTTP-Request-Standardelement direkt in HTTP(S) Test Script Recorder platzieren, dessen nicht leere Werte die in den anderen HTTP-Request-Standardwerten überschreiben. Weitere Informationen finden Sie unter Best Practices mit dem HTTP(S) Test Script Recorder .
Benutzerdefinierter Variablenaustausch
Wenn der HTTP(S) Test Script Recorder benutzerdefinierte Variablen (UDV) direkt in dem Controller findet, in dem Samples gespeichert werden, oder direkt in einem seiner übergeordneten Controller, weisen die aufgezeichneten Samples alle Vorkommen der Werte dieser Variablen auf durch die entsprechende Variable ersetzt. Auch hier können Sie benutzerdefinierte Variablen direkt im HTTP(S) Test Script Recorder platzieren, um die zu ersetzenden Werte zu überschreiben. Weitere Informationen finden Sie unter Best Practices mit dem Testskriptrekorder.
Ersetzung durch Variablen: Standardmäßig sucht der Proxy-Server nach allen Vorkommen von UDV-Werten. Wenn Sie beispielsweise die Variable WEB mit dem Wert www definieren , wird der String www überall dort durch ${WEB} ersetzt , wo er gefunden wird. Um zu vermeiden, dass dies überall passiert, aktivieren Sie das Kontrollkästchen „ Regex-Abgleich “. Dies weist den Proxy-Server an, Werte als Regexes zu behandeln (unter Verwendung der von ORO bereitgestellten perl5-kompatiblen Regex-Matcher).
Wenn " Regex Matching " ausgewählt ist, wird jede Variable in einen Perl-kompatiblen Regex kompiliert, der in \b( und )\b eingeschlossen ist . Auf diese Weise beginnt und endet jede Übereinstimmung an einer Wortgrenze.
Wenn Sie nicht möchten, dass Ihre Regex in diese Boundary-Matcher eingeschlossen wird, müssen Sie Ihre Regex in Klammern einschließen, z . B. ('.*?') , um mit 'name' von You can call me 'name' übereinzustimmen .
Wenn Sie nur eine ganze Zeichenfolge finden möchten, schließen Sie sie in (^ und $) ein, z. B. (^thus$) . Die Klammern sind erforderlich, da die normalerweise hinzugefügten Begrenzungszeichen verhindern, dass ^ und $ übereinstimmen.
Wenn Sie /images nur am Anfang einer Zeichenfolge abgleichen möchten , verwenden Sie den Wert (^/images) . Jakarta ORO unterstützt auch Null-Breiten-Look-Ahead, sodass man /images/… abgleichen kann, aber das nachgestellte / in der Ausgabe beibehalten kann, indem man (^/images(?=/)) verwendet .
Achten Sie auf überlappende Matcher. Zum Beispiel wird der Wert .* als Regex in einer Variablen namens regex teilweise mit einer zuvor ersetzten Variablen übereinstimmen, was zu etwas wie ${{regex} führen wird, was höchstwahrscheinlich nicht das gewünschte Ergebnis ist.
Wenn es Probleme beim Interpretieren von Variablen als Muster gibt, werden diese in jmeter.log gemeldet . Überprüfen Sie dies also unbedingt, wenn UDVs nicht wie erwartet funktionieren.
Wenn Sie mit der Aufzeichnung Ihrer Testmuster fertig sind, stoppen Sie den Proxy-Server (klicken Sie auf die Schaltfläche „ Stopp “). Denken Sie daran, die Proxy-Einstellungen Ihres Browsers zurückzusetzen. Jetzt möchten Sie vielleicht das Testskript sortieren und neu anordnen, Timer, Listener, einen Cookie-Manager usw. hinzufügen.
Wie kann ich auch die Antworten des Servers aufzeichnen?
Platzieren Sie einfach einen View Results Tree Listener als untergeordnetes Element des HTTP(S) Test Script Recorders und die Antworten werden angezeigt. Sie können auch einen Save Responses to a file Post-Processor hinzufügen , der die Antworten in Dateien speichert.
Anfragen mit Antworten verknüpfen
Wenn Sie die Eigenschaft proxy.number.requests=true definieren, fügt JMeter jedem Sampler und jeder Antwort eine Nummer hinzu. Beachten Sie, dass möglicherweise mehr Antworten als Stichproben vorhanden sind, wenn Ausschlüsse oder Einschlüsse verwendet wurden. Ausgeschlossene Antworten haben Labels, die in [ und ] eingeschlossen sind, zum Beispiel [23 /favicon.ico]
Cookie-Manager
Wenn der Server, gegen den Sie testen, Cookies verwendet, denken Sie daran, einen HTTP-Cookie-Manager zum Testplan hinzuzufügen , wenn Sie die Aufzeichnung abgeschlossen haben. Während der Aufzeichnung verarbeitet der Browser alle Cookies, aber JMeter benötigt einen Cookie-Manager, um die Cookie-Behandlung während eines Testlaufs durchzuführen. Der JMeter-Proxy-Server leitet alle vom Browser während der Aufzeichnung gesendeten Cookies weiter, speichert sie jedoch nicht im Testplan, da sie sich wahrscheinlich zwischen den Läufen ändern.
Autorisierungsmanager
Der HTTP(S) Test Script Recorder schnappt sich den " Authentication " Header und versucht, die Auth Policy zu berechnen. Wenn der Autorisierungs-Manager manuell zum Zielcontroller hinzugefügt wurde, findet HTTP(S) Test Script Recorder ihn und fügt die Autorisierung hinzu (übereinstimmende werden entfernt). Andernfalls wird der Autorisierungsmanager dem Zielcontroller mit dem Autorisierungsobjekt hinzugefügt. Möglicherweise müssen Sie automatisch berechnete Werte nach der Aufzeichnung korrigieren.
Hochladen von Dateien
Einige Browser (z. B. Firefox und Opera) geben beim Hochladen von Dateien nicht den vollständigen Namen einer Datei an. Dies kann dazu führen, dass der JMeter-Proxyserver fehlschlägt. Eine Lösung besteht darin, sicherzustellen, dass sich alle hochzuladenden Dateien im JMeter-Arbeitsverzeichnis befinden, indem Sie entweder die Dateien dorthin kopieren oder JMeter in dem Verzeichnis starten, das die Dateien enthält.
Aufzeichnen von HTTP-basierten, nicht textuellen Protokollen, die in JMeter nicht nativ verfügbar sind
Möglicherweise müssen Sie ein HTTP-Protokoll aufzeichnen, das nicht standardmäßig von JMeter verarbeitet wird (Custom Binary Protocol, Adobe Flex, Microsoft Silverlight, … ). Obwohl JMeter keine native Proxy-Implementierung zum Aufzeichnen dieser Protokolle bereitstellt, haben Sie die Möglichkeit, diese Protokolle aufzuzeichnen, indem Sie einen benutzerdefinierten SamplerCreator implementieren . Dieser Sampler Creator übersetzt das Binärformat in eine HTTPSamplerBase- Unterklasse, die dem JMeter-Testfall hinzugefügt werden kann. Weitere Details finden Sie unter "Erweitern von JMeter".
HTTP-Spiegelserver ¶
Der HTTP Mirror Server ist ein sehr einfacher HTTP-Server – er spiegelt lediglich die an ihn gesendeten Daten. Dies ist nützlich, um den Inhalt von HTTP-Anforderungen zu überprüfen.
Es verwendet den Standardport 8081 .

Parameter ¶
Parameter ¶
headerA: valueA|headerB: valueB würde headerA auf valueA und headerB auf valueB setzen .
Sie können auch die folgenden Abfrageparameter verwenden:
Parameter ¶
Eigenschaftsanzeige ¶
Die Eigenschaftsanzeige zeigt die Werte von System- oder JMeter-Eigenschaften. Werte können geändert werden, indem Sie neuen Text in die Spalte Wert eingeben.

Parameter ¶
Debug-Sampler ¶
Der Debug-Sampler generiert ein Beispiel, das die Werte aller JMeter-Variablen und/oder -Eigenschaften enthält.
Die Werte können im Bereich View Results Tree Listener Response Data angezeigt werden.

Parameter ¶
Postprozessor debuggen ¶
Der Debug PostProcessor erstellt ein SubSample mit den Details der vorherigen Sampler-Eigenschaften, JMeter-Variablen, Eigenschaften und/oder Systemeigenschaften.
Die Werte können im Bereich View Results Tree Listener Response Data angezeigt werden.

Parameter ¶
Testfragment ¶
Das Testfragment wird in Verbindung mit dem Include-Controller und dem Modul-Controller verwendet .

Parameter ¶
setUp-Thread-Gruppe ¶
Ein spezieller ThreadGroup-Typ, der zum Ausführen von Pre-Test-Aktionen verwendet werden kann. Das Verhalten dieser Threads ist genau wie ein normales Thread Group- Element. Der Unterschied besteht darin, dass diese Art von Threads ausgeführt wird, bevor der Test mit der Ausführung regulärer Thread-Gruppen fortfährt.

TearDown-Thread-Gruppe ¶
Eine spezielle Art von ThreadGroup, die verwendet werden kann, um Post-Test-Aktionen auszuführen. Das Verhalten dieser Threads ist genau wie ein normales Thread Group- Element. Der Unterschied besteht darin, dass diese Art von Threads ausgeführt wird, nachdem der Test die Ausführung seiner regulären Thread-Gruppen beendet hat.

